III.7. LA CODIFICA DEL CORPO DEL DOCUMENTO (<body>)
L'elemento <body>, secondo e più importante figlio di <text>, contiene l'intero corpo di un singolo testo unitario, con l'esclusione di ogni elemento preliminare o di appendice, contenuti invece all'interno dei tag <front> e <back>.
All'interno dell'elemento <body> ricorrono ovviamente una serie di suddivisioni, necessarie a definire la struttura interna del testo indagato; tali suddivisioni, evidenziate usualmente nella forma materiale del documento originale, mediante convenzionali pratiche tipografiche: spaziature, pagine bianche, stili di carattere; ricalcano le tradizionali partizioni strutturali che hanno comunemente assunto dei nomi ben precisi in relazione al genere cui il testo appartiene: "capitolo", "paragrafo", "sezione", "parte", per la prosa; "poema", "canto", per la lirica; "atto", "scena", per il dramma.
Al livello più basso l'articolazione interna di un testo in prosa è delimitata dai paragrafi, nella codifica questa suddivisione è esplicitata usando il marcatore <p>, il corpo di un testo in prosa può essere costituito soltanto da una serie di paragrafi, tuttavia abitualmente tali paragrafi sogliono essere raggruppati insieme in capitoli, sezioni, sottosezioni, etc..
Lo schema TEI adotta i tag <div#> per rendere nella codifica queste segmentazioni di più alto livello del contenuto testuale. Gli elementi <div#> appartengono ad una famiglia di marcatori, che va da <div0>[141] sino a <div7> per mezzo dei quali vengono rappresentate gerarchicamente le partizioni strutturali dell'opera; ad esempio in un'opera divisa in capitoli, sezioni e sottosezioni adotteremo il tag <div0> per delimitare i capitoli, <div1> per le sezioni e <div2> per le sottosezioni. Accanto agli elementi <div#> numerati esiste un elemento <div> non numerato, il quale può ricorrere all'interno di altri elementi <div>, senza limiti alla profondità di annidamento. Questo marcatore, che abbiamo già incontrato in occasione delle epigrafi e della dedica presenti nell'avantesto, viene utilizzato per marcare quelle sezioni di cui non si vuole o non si può rendere esplicitamente la posizione gerarchica nell'articolazione strutturale del documento, oppure per rappresentare, alternativamente al sistema dei <div#> numerati, quei testi in cui siano presenti più di otto livelli nell'impianto organizzativo dell'opera.
Lo schema di Baltico è abbastanza semplice, il libro consta di due parti che raggruppano rispettivamente diciassette capitoli la prima, ventiquattro, o meglio ventitre più la conclusione, la seconda. Nella codifica abbiamo reso questa organizzazione dell'opera adoperando il tag <div0>, come elemento divisore di livello più alto, per identificare le due parti, mentre i singoli capitoli, al secondo livello nella scala gerarchica dell'albero del documento, sono stati racchiusi all'interno di marcatori di tipo <div1>.
Ecco graficamente come si presenta la struttura del <body> di Baltico:
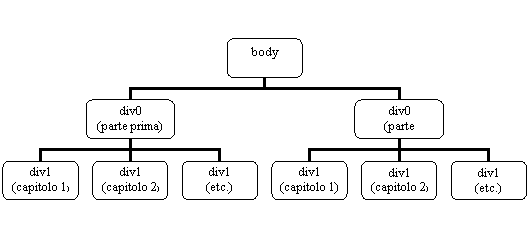
III.7.1. <div1>
Come già fatto, per discutere delle modalità di codifica dei singoli capitoli riportiamo la riproduzione grafica di una pagina del libro e di seguito la versione codificata di quella stessa pagina.
Ecco come si presenta nel testo fonte pagina 15, prima pagina del primo capitolo della prima parte dell'opera:

Ecco la stessa pagina nella codifica XML/TEI:
<pb n="15"/>
<div1 type="cap" n="1" id="I.1">
<head type="ord">I</head>
<head type="tem">L'ubriaco che sapeva auscultare la terra</head>
<p>
Dalle parti di <rs type="luogo.real">Montedoro</rs> dicono che fu un pastore, per caso. Quel pastore, all'aperto, stava facendo bollire del latte in un calderone; fuoco di legna, sotto. Toccata dal fuoco una pietra cominciò a bruciare e a mandare fumo e a spargere odore da intossico. Sotto gli occhi del pastore la pietra si liquefece, si ridusse ad un rivoletto giallobruno. Il pastore tastò con la punta del bastone e un po' di quella materia, pastosa e incandescente, vi rimase attaccata. E quella sostanza, accostata alla legna del focolare, vi riaccendeva il fuoco o lo ravvivava. Uno zolfanello, insomma.
</p>
<p>
Così si racconta a <rs type="luogo.real">Montedoro</rs> e in altre contrade, ma non è questa la sola diceria. A detta di molti che oggi riposano del più profondo, un tipo balzano non ebbe le allucinazioni quel pomeriggio che, stravaccato a smaltire la sbornia sotto un ulivo, attraverso una bene ordinata fila di formiche, tra zolle essiccate scoprì il minuscolo ingresso dal quale si raggiungeva uno sterminato tesoro. Una formica, non più grossa delle altre, attirò la sua attenzione emersa per qualche secondo dal molle pantano in cui affondava. La formica trascinava una pietruzza gialla, di un giallo brillante, oro si sarebbe detto. E altre formiche trascinavano pietruzze gialle e tutte affioravano
[...]
</p>
[...]
</div1>
Nella codifica ogni capitolo viene aperto dal marcatore <div1> associato a tre attributi: type designa la tipologia della partizione, il valore cap, abbreviazione comunemente usata sia in TIL sia in GriseldaOnLine, indica che si tratta di un capitolo. L'attributo n specifica un breve nome mnemonico o un numero per la divisione, nel nostro caso indica il numero di capitolo all'interno della parte. L'attributo id, infine, fornisce un identificatore univoco per la divisione, tale attributo non può presentarsi col medesimo valore in nessun altro elemento, pena l'invalidità sintattica del documento; id serve ad identificare in modo unico ed inequivocabile un elemento e può essere usato per i riferimenti incrociati o per altri collegamenti. Nel caso di Baltico il valore di id in <div1> è dato dal numero romano della parte cui il capitolo appartiene, separato con un punto dal numero arabo indicante il numero di capitolo all'interno della parte, come vedremo in seguito, nella produzione dei formati di output, l'attributo id è stato molto utile per la realizzazione di sistemi di collegamenti e riferimenti di vario tipo.
III.7.2. <head>
Subito dopo il tag <div1>, che può essere considerato come una sorta di contenitore del capitolo, inizia la codifica del testo vero e proprio. Come possiamo vedere nella riproduzione grafica della pagina, ogni capitolo si apre con i titoli in grassetto. Nella codifica TEI titoli ed intestazioni dei blocchi di tipo <div#> vengono marcati grazie all'elemento <head>, mediante l'attributo type si indica il tipo di titolo, i valori fra cui si è scelto, già adottati sia in ambito TIL sia da GriseldaOnLine, sono:
- conv (convenzionale) per i titoli convenzionali come "Capitolo Primo", "Parte I";
- ord (ordinale) per i titoli limitati a soli numeri arabi o romani;
- tem (tematico) per i titoli tematici in genere costituiti da pochi sintagmi;
- desc (descrittivo) per i titoli descrittivi più lunghi.
Nel nostro testo i capitoli vengono introdotti da due titoli uno di tipo ordinale in numeri romani ed uno di tipo tematico, per tale motivo abbiamo adottato due volte il marcatore <head> una volta con valore ord e la seconda con valore tem per codificare le intestazioni del capitolo.
III.7.3. Paragrafi
I paragrafi costituiscono la più piccola unità strutturale di un testo in prosa. Nella codifica i paragrafi sono delimitati dall'elemento <p>; nella pratica tipografica moderna l'inizio di un nuovo paragrafo è tipicamente contraddistinto da un rientro a destra nella prima riga, proprio sulla base dei rientri nel testo fonte, come si può vedere, abbiamo marcato i singoli paragrafi nel codice.
III.7.4. Salti di pagina
Nella pagina di esempio riportata sopra, immediatamente prima del tag di apertura del blocco <div1> incontriamo l'elemento <pb n="15"/>; <pb> (page break - interruzione di pagina) è l'elemento deputato a segnalare nella codifica i salti di pagina presenti nel testo fonte delimitando i confini tra le pagine in un sistema di riferimento standard. L'elemento <pb> appartiene alla classe dei cosiddetti elementi "milestone", in italiano "pietra miliare", questi elementi non marcano come gli altri delle porzioni più o meno estese di testo, bensì servono ad identificare dei punti di riferimento all'interno del contenuto testuale, come si sarà notato <pb> è infatti un tag autonomo che non prevede un tag di chiusura. Nella codifica dei salti pagina ci siamo attenuti fedelmente a quanto suggerito nelle guidelines TEI, in ciò discostandoci sia dalla metodologia adottata da GriseldaOnLine sia, probabilmente[142], da TIL; i <pb> sono stati da noi inseriti in cima alla pagina cui fanno riferimento, o, per essere più precisi, all'inizio di quella porzione di testo codificato corrispondente con il contenuto di una pagina nella fonte di riferimento; mediante l'attributo n è stato indicato in forma normalizzata il numero associato nella fonte alla pagina che segue il punto di inserimento; GriseldaOnLine, invece, ha inserito il tag per codificare i page break di seguito all'ultima parola che compare nella pagina, nella sostanza, la differenza con il metodo da noi adottato, che ricordiamo è quello consigliato dal manuale ufficiale TEI, sono minime, i <pb> nel testo codificato vengono a cadere quasi sempre nello stesso punto con ambedue le metodologie, tuttavia la pratica di codifica adottata da GriseldaOnLine presenta un ovvio inconveniente per la prima ed ultima pagina del testo.[143]
Una precisazione, allorché un salto pagina nell'edizione di riferimento spezza una parola sillabandola, abbiamo posto il tag <pb> dopo questa parola, assumendo che essa appartenga alla pagina in cui inizia.
Si sarà notato che nel testo codificato ricorrono anche degli elementi, che marcano alcune parole, come ad esempio <rs type="luogo.real">Montedoro</rs>, di questo come degli altri elementi intralineari parleremo nel prossimo paragrafo.
III.7.5. Elementi intralineari
All'interno dei vari elementi strutturali (<div#>, <p> etc.) la codifica TEI prevede tutta una serie di elementi, conosciuti come "elementi intralineari", che di norma si applicano a singoli termini oppure a sequenze di parole o frasi, i quali vengono principalmente usati per marcare i nomi di persona e luogo, le date, i discorsi diretti nei testi in prosa e diversi altri fenomeni di evidenziazione.
III.7.6. Nomi ed espressioni referenziali
Leggiamo nel manuale Tei-Lite "Una espressione referenziale è un'espressione che si riferisce ad una persona, un luogo, un oggetto, etc."; lo schema TEI prevede due elementi per codificare queste espressioni <rs> e <name>, <rs> è in genere usato per nomi o espressioni referenziali generiche, <name> contiene invece nomi propri o espressioni sostantivali.
III.7.7. Nomi propri
Nella codifica di Baltico tutti i nomi propri sono stati racchiusi all'interno del tag <name>. Riportiamo a titolo d'esempio alcuni nomi incontrati nel romanzo di Collura oggetto della nostra analisi:
<name type="persona.real" key="Henry Temple Palmerston">Henry Temple Palmerston</name>
<name type="persona.real" key="Giuseppe Garibaldi">Garibaldi</name>
<name type="persona.fit" key="Bartolomeo Ardito">Bartolomeo Ardito</name>
<name type="persona.fit" key="Speranza Ardito">Speranza Ardito</name>
Come si può rilevare mediante l'attributo type si è specificato se il nome faccia riferimento ad una persona reale oppure ad un personaggio di fantasia. I valori possibili nel nostro testo per l'attributo type sono stati pertanto "persona.real" per i personaggi reali, "persona.fit" per i personaggi di fantasia. La distinzione *.real *.fit, tra soggetti reali oppure fittizi, non è stata adoperata esclusivamente per i nomi propri ma per tutte le espressioni referenziali codificate nel testo.
Siamo in primo luogo debitori ai codificatori dei testi elettronici del portale GriseldaOnLine, che come noi hanno adottato la TEI-Lite, nella scelta di questo sistema di denominazione dell'attributo type di tali marcatori; in verità una simile distinzione è presente anche nei testi TIL, tuttavia essendo stato, per questi ultimi, adottato l'intero schema TEI, si sono talvolta utilizzati dei tag diversi nella marcatura delle espressioni referenziali, quali ad esempio <persName> e <placeName> non previsti dalla TEI-Lite.
All'elemento <name> si accompagna anche un altro attributo, key grazie al quale si fornisce una sequenza di caratteri che identifica in modo univoco un personaggio nel contesto dell'opera.
III.7.8. Nomi di luogo ed altre espressioni referenziali
Tutti i nomi di luogo sono stati codificati mediante il tag <rs>; si ricorderà, ad esempio, <rs type="luogo.real">Montedoro</rs> che abbiamo incontrato nella porzione di codice riportata nelle pagine precedenti; come si vede si è mantenuta la distinzione *.real *.fit già adottata per i nomi propri. Oltre che per i toponimi con <rs> si sono marcati anche altri termini giudicati rilevanti, i valori dell'attributo type nella codifica di Baltico sono: luogo.real; luogo.fit; famiglia.fit; soprannome.fit; istituzione.real; societa.real (manca l'accento perché altrimenti alcuni parser non considerano ben formato il file); zolfara.real. Si noti che in alcuni casi mediante i valori di <rs> si è fornita una specificazione ulteriore di quelli che genericamente avrebbero potuto essere codificati come nomi o luoghi, in particolare abbiamo preferito adottare zolfara.real invece di luogo.real, in quanto il tema dell'estrazione dello zolfo in Sicilia è uno degli argomenti principali dell'opera, abbiamo pertanto optato per dedicare una particolare attenzione a questo elemento in vista di eventuali esigenze di analisi e di interpretazione del testo.
Questi elementi appena descritti, come d'altronde quasi tutti gli elementi TEI, sono portatori principalmente di quella che potremmo definire meta-informatività interna, grazie a questi marcatori si specifica meglio il valore e la funzione del contenuto testuale dell'opera, si dà, in pratica, significato al testo elettronico cosicché applicazioni informatiche possano agevolare studiosi e lettori in genere del testo nell'analisi e nella fruizione dello stesso, si pensi ad esempio ai programmi di trattamento automatico del linguaggio naturale oppure ai già citati software di infromation retrival.
III.7.9. Riferimenti temporali
Tra gli elementi del testo che lo schema di codifica TEI prevede siano sottoposti ad un'opportuna marcatura vi sono date ed orari; i tag designati all'identificazione dei riferimenti temporali sono <date> e <time>. Mediante l'attributo value viene indicato il valore normalizzato della data in un formato standard, ad esempio l'espressione "nove di luglio del duemila" verrà così codificata <date value="09-07-2000">9 di luglio del duemila</date>, le Guidelines TEI consigliano di adottare lo standard ISO 8601:2000 basato sullo schema aaaa-mm-gg (anno-mese-giorno) nella rappresentazione dei valori dell'attributo, tuttavia tale sistema è ben poco utilizzato in Italia, perciò abbiamo ritenuto opportuno conformarci alla forma canonica gg-mm-aaaa (giorno-mese-anno) abitualmente adoperato nei nostri lidi ed adottato da tutti gli altri progetti di codifica italiani. Per quanto riguarda le date parziali, ad esempio 1988, nove luglio, abbiamo proceduto, al fine di evitare fraintendimenti, sostituendo la parte mancante del riferimento temporale con delle "X", le date riportate poco sopra nella codifica si presenterebbero ad esempio così:
<date value="xx-xx-1988">1988</date>,
<date value="09-07-xxxx">9 luglio</date>.
Nella codifica di Baltico non è servito mai il tag <time>, il suo uso, comunque, è analogo a quello di <date>.
III.7.10. Discorso diretto e citazioni
Uno dei tag per la marcatura di fenomeni intralineari, che più spesso ricorre nella codifica TEI di Baltico, è <q>. Questo elemento, citiamo testualmente il manuale TEI-Lite, "contiene una citazione, manifesta o meno - una rappresentazione di discorso o pensiero marcata come se fosse espressa da qualcun altro (sia essa realmente citata o meno); in narrativa, le parole sono di solito quelle di un personaggio o di chi parla; nei dizionari, <q> può essere usato per indicare esempi, reali o inventati, dell'uso di un termine."[144] Principalmente <q> è utilizzato per codificare il discorso diretto, prima di esaminare nei dettagli le caratteristiche di questo elemento riportiamo a titolo di esempio, alcuni paragrafi del testo codificato del romanzo ricchi di discorso diretto:
<p>
<q type="diretto" who="Sebastiano Azzalora">«Chi ti ha avvelenato?» lo accolse l'amico.</q>
</p>
<p>
<q type="diretto" who="Raimondo Battaglia">«I pensieri non mi fanno dormire. E dai pensieri nascono le idee. Ne ho una che farà parlare, qui intorno»</q>. <name type="persona.fit" key="Raimondo Battaglia">Raimondo Battaglia</name> aveva gli occhi infebbrati e le mascelle tremanti.
</p>
<p>
<q type="diretto" who="Sebastiano Azzalora">«Se non si dorme s'impazzisce»</q>. <name type="persona.fit" key="Sebastiano Azzalora">Sebastiano Azzalora</name> riprese a zappare.
</p>
<p>
<q type="diretto" who="Raimondo Battaglia">«In questa terra c'è un tesoro: basta scavare. Ma non per fare quello che stai facendo tu. Se riusciamo a mettere le mani sullo zolfo diventeremo ricchi»</q>. Urlava, non parlava, <name type="persona.fit" key="Raimondo Battaglia">Raimondo Battaglia</name>.
</p>
<p>
<q type="diretto" who="Raimondo Battaglia">«Qui sotto c'è zolfo, e laggiù c'è zolfo, e laggiù, e ovunque riesci a vedere. Basta avere i mezzi per arrivarci»</q>.
</p>
Come si sarà notato ogni battuta dei due personaggi Raimondo Battaglia e Sebastiano Azzalora è racchiusa dal tag <q>, normalmente nei testi a stampa il discorso diretto è introdotto e delimitato da particolari caratteri come le virgolette o i trattini lunghi, nel testo del nostro esempio il discorso diretto è marcato dalle doppie virgolette ad angolo, o meglio dalle rispettive entità numeriche (« corrisponde al carattere [«] mentre » al carattere [»]) che come si può vedere sono inserite all'interno dell'elemento <q>.
Due attributi, type e who, specificano il valore di questo marcatore; type viene in genere usato per indicare se il brano sia parlato o pensato, se rappresenti un discorso diretto oppure, ad esempio, un monologo interiore. Nella nostra codifica abbiamo dato a questo attributo il valore "diretto" oppure "pensato" a seconda delle esigenze poste dalla narrazione. Col secondo attributo who si identifica colui che pronuncia il discorso, ove possibile il valore di who corrisponde con la chiave associata al nome del personaggio nell'attributo key del tag <name>. Spesso tuttavia il parlante non è identificato precisamente con il nome durante la narrazione ma piuttosto attraverso un titolo ovvero un'elemento distintivo fisico o morale, in questo caso si è preferito qualificarlo nel tag per mezzo di queste caratteristiche, ad esempio: uomo dai rattoppi multicolori, vecchio monaco, sicari, ubriacone etc..
In taluni casi però viene a mancare anche questa minima caratterizzazione del personaggio, o altrimenti si fa troppo labile; spesso, inoltre, viene riportata come discorso diretto la voce popolare, in tutti questi casi si è adoperato un valore generico "personaggio/i indefinito/i", "popolo indefinito" per l'identificazione del parlante mediante l'attributo who.
Come già accennato in precedenza il tag <q>, accompagnato dall'attributo type con valore citazione (<q type="citazione">...</q>), è servito anche per delimitare le citazioni presenti nel testo. Si è deciso nella codifica, mediante l'attributo rend, di registrare, ove necessario, in che modo è stampata la citazione nella fonte materiale, i valori usati nell'attributo per far ciò sono stati: bloc per citazioni messe in risalto in un blocco di testo graficamente autonomo ed italic per le citazioni in corsivo.
Alcune citazioni in Baltico riportano dei brevi brani di testo in versi, come ad esempio la citazione presente a pagina trenta del libro, che riportiamo di seguito:
<pb n="30"/><p>
<q type="diretto" who="Serafino Collica">«Può sbagliarsi <name type="persona.real" key="Dante Alighieri">Dante</name>?»</q> disse quasi a se stesso. Poi, assaporando lo sgorgare dei versi. scandì
<q type="diretto" who="Serafino Collica">
<q type="citazione" rend="bloc">
<lg part="N" type="terzina">
<l>«E la bella <rs type="luogo.real">Trinacria</rs>, che caliga</l>
<l>tra <rs type="luogo.real">Pachino</rs> e <rs type="luogo.real">Peloro</rs> sopra 'l golfo</l>
<l>che riceve da Euro maggior briga,</l>
</lg>
<lg part="Y" type="terzina">
<l>non per Tifeo ma per nascente solfo,</l>
<l>attesi avrebbe li suoi regi ancora...</l>
</lg>
</q>
È tutto scritto, basta saper leggere»</q>.
</p>
Il personaggio Serafino Collica pronuncia i celebri versi[145] dell'ottavo canto del Paradiso, i quali, all'interno della citazione, sono stati marcati nella codifica per mezzo dei tag dello schema TEI specifici per la lirica.
L'elemento <lg> contiene un gruppo di versi che costituiscono un'unità formale, come ad esempio una stanza, un refrain etc.; l'attributo part specifica se l'unità strofica contenuta all'interno di <lg> è completa o meno, tornando al nostro esempio vediamo che la prima terzina essendo riportata nella sua interezza presenta l'attributo part con valore N[146], della seconda terzina invece sono citati soltanto i primi due versi pertanto l'attributo part in questo caso ha valore Y. Con l'attributo type si indica il tipo di blocco strofico marcato da <lg>, nella circostanza trattandosi di una terzina dantesca abbiamo adottato il valore terzina. All'interno di <lg> i singoli versi sono delimitati dal tag <l>, analogamente ad <lg> anche <l> può essere associato all'attributo part per specificare la completezza metrica o meno del verso.
Un altro caso particolare di citazione è rappresentato dal capitolo ventidue della parte seconda di Baltico dal titolo "Dove fedelmente si trascrive una lettera trovata per caso". Come già si evince dal titolo, in questo capitolo si riporta una lettera che un emigrato in America invia ai propri cognati in Sicilia. L'intero capitolo può essere considerato una lunga citazione e ad avvalorare questa ipotesi vi è il fatto che il testo del capitolo è completamente in corsivo. Assai difficoltosa è stata la decisione su come rendere nella codifica questo capitolo, alla fine abbiamo scelto di rifarci alle indicazioni contenute nel manuale del progetto BibIt ed abbiamo così trascritto nel codice il capitolo:
<pb n="200"/>
<div1 type="cap" n="22" id="II.22">
<head type="ord">XXII</head>
<head type="tem">Dove fedelmente si trascrive una lettera trovata per caso</head>
<q type="epistola" >
<text>
<body>
<opener rend="italic">
<salute>Cari cognati <name type="persona.fit" key="Sebastiano">Sebastiano</name> e <name type="persona.fit" key="Raimondo">Raimondo</name>.</salute>
</opener>
<p rend="italic">
Ho ricevuto la vostra lettera e piango ancora per le cose tristi che mi avete scritto. Sappiate, però, che la vostra adorata sorella <name type="persona.fit" key="Rosetta">Rosetta</name> sta bene e vi manda tanti cari saluti.
[ . . . ]
</p>
<closer rend="italic">
<salute>Aspettando vostre notizie vi mando un forte abbraccio e tanti fraterni saluti anche da parte di vostra sorella <name type="persona.fit" key="Rosetta">Rosetta</name> che vi prega di questo: quando capita che qualcuno di
<rs type="luogo.real">Grotte</rs> parte per
l'<rs type="luogo.real">America</rs>, mandatele un fiore di zolfo. Sceglietela voi una bella pietra brillante, perché, testa sbadata, non ha più trovata quella che le avevo regalato io tanti anni fa. Decidetevi a venire, che
l'<rs type="luogo.real">America</rs> è grande e c'è posto per tutti. Ancora fraterni saluti dal vostro caro cognato </salute><signed>
<name type="persona.fit" key="Pinzello Rosario">Pinzello Rosario</name></signed>.
</closer>
</body>
</text>
</q>
</div1>
Per comodità abbiamo riportato solamente la parte iniziale e quella finale del capitolo.
Come si può vedere il testo del capitolo riportante l'epistola è interamente racchiuso all'interno dell'elemento <q type="epistola"> , in questo soltanto ci siamo, necessariamente, discostati dalle indicazioni del manuale BibIt, il quale invece prescrive l'utilizzo dell'elemento <quote> che, come abbiamo già avuto modo di verificare, non è incluso nella DTD TEI-Lite.
Essendo la citazione costituita da un testo completo, nello specifico un'epistola, sulla scorta di quanto indica il manuale del progetto Biblioteca Italiana (BibIt), essa è stata codificata all'interno di <q> dentro un elemento <text>, seguito da <body>. Per la marcatura del testo della lettera si sono usati i tag specifici per la codifica delle epistole, le formule di apertura e chiusura delle lettere sono contenute dentro gli elementi <opener> e <closer>, i quali racchiudono alcuni elementi tipici che a loro volta sono codificati mediante ben determinati tag: <dateline> contiene le indicazioni di tempo e luogo di una lettera, <byline> contiene invece le indicazioni di responsabilità di una lettera, <salute> è usato per le formule di saluto e le dediche, mentre <signed> viene adoperato per la firma dell'autore in calce a una epistola.
<http://www.tei-c.org/Lite/teiu5_it.htm>
(ed. orig. TEI U5: Encoding for Interchange: an introduction to the TEI, <http://www.tei-c.org/Lite/teiu5_en.tei>).
gennaio 1998, (20 febbraio 2004).