III.17. ANALISI ED INTERPRETAZIONE
vedi: appendice 18, appendice 19, appendice 20, appendice 21, appendice 22.
Sin da principio tra gli obiettivi di questa relazione non vi sono stati l'analisi e lo studio "tradizionale" del romanzo di Matteo Collura Baltico, il quale più che altro ha costituito la "cavia" per i nostri esperimenti di codifica e trattamento informatico del testo; nonostante ciò, nel momento in cui ci apprestiamo a concludere la nostra esposizione, appare utile il tentativo di fornire un abbozzo di analisi dell'opera letteraria, da noi sottoposta a codifica, giovandoci del supporto di tutti quegli strumenti che sino ad ora sono stati, per lo più, adoperati per la rappresentazione del testo piuttosto che per la sua interpretazione; potremmo dire che proprio su quella linea "sperimentale", che ha un po' costituito il filo conduttore delle nostre attività si inseriscono i lavori che illustreremo fra breve e che primariamente mirano a dimostrare l'utilità della codifica elettronica anche nell'analisi dei testi.
Un'epopea siciliana, recita il sottotitolo del romanzo di Collura fornendoci un'importante chiave di lettura dell'opera, in cui lo scrittore agrigentino mette in scena l'epopea dello zolfo e degli zolfatari. La vicenda si sviluppa in un arco di tempo, che va dalla prima metà dell'ottocento (il riferimento temporale è fornito dalla narrazione dell'emersione nel Canale di Sicilia dell'isola Ferdinandea) sino agli anni Sessanta del Novecento. Teatro della vicenda è la cittadina di Grotte in provincia di Agrigento, paese natale del padre dello scrittore, elemento questo rilevante in quanto ha costituito il primo spunto per la genesi del romanzo, come ci rivela lo stesso scrittore nella nota finale: "All'inizio avevo pensato ad un racconto che raccogliesse le cose che mio padre, grottese, mi narrava sugli zolfatari del suo paese". Ma nella narrazione, al livello della memoria si affianca quello della storia, e così il racconto finisce per diventare non soltanto la storia dell'ascesa e del successivo declino di un paese di zolfatari, ma delle opportunità mancate, delle aspettative disattese e, sono parole dello scrittore, "dell'eterno fallimento delle speranze dei siciliani". Baltico è un romanzo atipico, come brillantemente ha osservato la Prof. Lucrezia Lorenzini in occasione del suo intervento "Microstorie frantumate" in Baltico di Matteo Collura[232], costituito da "microstorie frantumate", un insieme di racconti strettamente interrelati fra di loro in modo tale da costituire un unicum narrativo; nota ancora Lucrezia Lorenzini come Baltico sia "racconto di documenti e di favole, di universo mentale e di mito", romanzo corale che attraverso una folla di personaggi rappresenta il tema principale dell'avventura delle zolfare, su cui si innesta l'altro grande tema del romanzo, l'emigrazione dei siciliani a cavallo fra Ottocento e Novecento. Ma questi temi non vengono svolti attraverso gli occhi e le vicende di un personaggio principale; il narratore eterodiegetico attraverso i casi e le parole di una folta pletora di personaggi, in molti casi figure appena sbozzate o addirittura voci indefinite di un vasto "coro", tesse una tela di vicende e rapporti che costituiscono il tessuto della narrazione; una narrazione fatta di "documenti e favole", di esperienze umane e vicende storiche, di "universo mentale e mito"; un caleidoscopio di situazioni e figure, in cui non spicca un protagonista, eroe dell'azione su gli altri personaggi, fatta eccezione forse per il "gigante" Bartolomeo; ma a ben guardare anche la vicenda di Bartolomeo Ardito e del suo desiderio di vedere il Baltico, metafora dell'"altrove", del sogno e della speranza che diverranno l'America, l'Australia e tutte quelle terre in cui approderanno i numerosi siciliani in fuga dalla miseria e dall'arretratezza: è soltanto una delle tante storie, uno dei tanti fili intrecciati che, come in un arazzo, formano l'intero disegno.
Potremmo forse dire che è proprio il paese di Grotte il protagonista della narrazione, Grotte nel racconto rappresenta l'osservatorio della realtà isolana durante la stagione dello zolfo, osservatorio che tuttavia assurge a metafora e simbolo della Sicilia tutta, microcosmo che rispecchia il macrocosmo di cui fa parte.
Dopo questa necessaria premessa passiamo a vedere come abbiamo ipotizzato si potesse utilizzare il testo codificato di Baltico per cercare di investigare l'opera. È, tuttavia, bene puntualizzare che quello che ci apprestiamo a mostrare è soltanto un esperimento, una esemplificazione delle opportunità offerte dalla codifica dichiarativa XML/TEI agli studiosi, con tutte le limitazioni del caso. Occorre, inoltre precisare che la nostra codifica dell'opera di Collura non è stata rivolta alle esigenze dell'interpretazione e dell'analisi, ma è stata piuttosto una codifica "minima" con finalità principalmente di distribuzione ed integrazione in archivi digitali.
D'altronde, la codifica stessa può essere funzionale all'indagine letteraria e prospettarsi, per certi versi, come attività di interpretazione del testo, fornendo così un nuovo utile strumento agli studiosi.
Se si ricorda la definizione che di codifica informatica del testo abbiamo fornito, seguendo le idee di Fabio Ciotti, all'inizio della trattazione come rappresentazione formale di un testo ad un qualche livello descrittivo, si comprenderà il valore che la codifica può rappresentare anche in attività di studio dei testi, ove appunto il fine della marcatura del testo sia orientato alla rappresentazione di un livello descrittivo utile all'analisi dello stesso; ad esempio, sono realizzabili codifiche dei testi indirizzate ad evidenziare fenomeni linguistici oppure ancora l'evoluzione del testo nelle varianti, oltre ad innumerevoli altri tipi di codifica caratterizzate da un approccio al testo ogni volta differente sulla base di diverse esigenze analitiche. Il codificatore è in primo luogo un lettore "attento" del testo che evidenzia, annota, mediante il markup determinate porzioni di testo sulla base di specifiche esigenze, rappresentative o interpretative, in vista di un successivo trattamento delle informazioni da lui codificate con l'ausilio di strumenti informatici. Vorremmo dire che la codifica informatica dichiarativa dei testi potrebbe prospettarsi come una forma di approccio alternativo all'analisi delle opere letterarie, quasi un'attività propedeutica all'interpretazione ed allo studio dei testi, ferma restando l'importanza delle forme tradizionali di indagine; è bene, tuttavia, tener presente che l'analisi eseguita con l'ausilio di strumenti informatici non è da vedersi come sostitutiva delle forme tradizionali di approccio analitico ai testi letterari; semmai, va considerata come complementare ed integrativa proprio a quelle metodiche di studio.
Un piccolo esempio di quanto appena sostenuto lo abbiamo cercato di fornire nei lavori che ci apprestiamo ad illustrare. Torniamo a rammentare che quella che stiamo per mostrare è solo un'esemplificazione delle potenzialità offerte allo studioso dalle codifiche dichiarative nell'interpretazione dei testi; ricordiamo, inoltre, che quella da noi effettuata è stata una codifica "minimale": avremmo, infatti, potuto soffermarci su particolari aspetti del testo oppure cercare di sottolineare particolari livelli della narrazione o eventuali fenomeni linguistici per poi sottoporli ad analisi con gli strumenti automatici, ma in sede di codifica non siamo stati mossi dalle esigenze dell'analisi letteraria, ma soprattutto, come detto, da quelle della rappresentazione del testo. Nonostante ciò siamo riusciti senza eccessivo sforzo ad approntare due piccoli lavori, che esemplificano e dimostrano come è possibile utilizzare gli strumenti dedicati al trattamento dei dati XML, piegandoli ed adattandoli agli scopi dell'analisi ed interpretazione dei testi.
Abbiamo precedentemente affermato che uno dei caratteri distintivi di Baltico è la "coralità", proprio per aiutarci ad analizzare questo aspetto dell'opera abbiamo approntato il primo foglio di stile XSLT che adesso passiamo ad analizzare ed il cui codice, come di consueto, è riportato in appendice. Finalità di questo foglio è quella di fornire alcuni dati sul testo, naturalmente opera sulla base degli elementi da noi codificati nel sorgente XML; l'output in formato puro testo ci offre alcuni dati sul numero dei personaggi (suddividendoli per tipologia) e dei discorsi diretti, dopodiché restituisce l'elenco completo dei personaggi e dei parlanti. Passando ad un'analisi più precisa del foglio XSLT vediamo che il primo comando <xsl:value-of> opera su tutti gli elementi <name> del sorgente in cui il valore dell'attributo type sia persona.fit, questo comando in realtà non fornisce come indicato nell'etichetta dell'output il numero dei personaggi di fantasia del testo, bensì indica il numero di tutti gli elementi <name> che hanno un attributo type=persona.fit; è ovvio che l'utilità di questo componente come del successivo, considerando che normalmente un nome ricorre per più di una volta, è abbastanza opinabile, abbiamo deciso comunque di mantenerli per mostrare con diversi esempi come sia possibile estrapolare dati di vario tipo e natura (sulla base degli elementi codificati) da un sorgente XML/TEI.
In Baltico la coralità si estrinseca principalmente mediante l'ampio ricorso al discorso diretto, serve ad evidenziare questo aspetto della scrittura di Collura il terzo comando <xsl:value-of> del foglio di stile che stiamo osservando, che ci fornisce il numero totale dei discorsi diretti presenti nel testo, come sappiamo identificati nel sorgente dal tag <q> accompagnato dall'attributo type con valore diretto; l'output dell'elaborazione ci informa che lo scrittore agrigentino si è servito nella sua narrazione del discorso diretto per ben 827 volte, fatto questo che attesta l'importanza del dialogo drammatico nell'economia del racconto, denotato dalla presenza di una narrazione a focalizzazione zero assai discreta che spesso preferisce commentare o raccontare attraverso il dialogo tra i numerosi personaggi "coro". Proprio sul "coro" dei personaggi focalizza la propria attenzione il resto del foglio di stile che stiamo esaminando. Abbiamo precedentemente affermato che spesso sono personaggi indefiniti, figure appena sbozzate, le voci di questo vasto "coro"; cerca di evidenziare questo aspetto il quarto elemento <xsl:value-of> del foglio XSLT, il quale restituisce il numero di tutti gli elementi <q> in cui il parlante sia di tipo indefinito, o meglio, per esser precisi, in cui nell'attributo who, che specifica il parlante, sia contenuto il termine indefinito oppure indefiniti. L'output ci informa che ciò accade per ben 246 volte, fatti i dovuti calcoli vediamo che ben il 29.75%, quindi quasi un terzo, dei discorsi diretti del romanzo è pronunciato da personaggi indefiniti, si tenga inoltre presente che questo numero è errato per difetto, in quanto in fase di codifica non abbiamo dedicato ampia attenzione a questo aspetto, anzi dobbiamo confessare di esserci resi conto della rilevanza di questo fenomeno proprio esaminando i dati preliminari delle prime versioni di prova di questo foglio di stile, quindi un buon numero di personaggi che potremmo far rientrare nella categoria degli "indefiniti" è identificato mediante un appellativo generico (ad es. brigadiere, capicantiere) ovvero un soprannome o un'altra caratteristica, sarebbe bastato in sede di codifica aggiungere all'identificativo contenuto nell'attributo who di <q> il termine indefinito/i per farli rientrare nel computo indicato sopra[233]. Proprio nel tentativo di approfondire il tema del numero dei personaggi e soprattutto dei parlanti abbiamo impostato le due elaborazioni <xsl:for-each> del foglio di stile, la prima restituisce l'elenco di tutti i nomi di personaggi di fantasia, ben più utile, la seconda invece fornisce la sequenza, disposta in ordine alfabetico, di tutti i valori degli attributi who degli elementi <q> marcanti discorsi diretti, e quindi, in pratica, l'elenco di tutti i parlanti. Visti così questi dati possono apparire poco utili; in realtà, invece, trattati con l'ausilio di altri programmi riescono a fornirci delle valide informazioni; nello specifico abbiamo operato in questo modo: abbiamo dapprima importato l'elenco dei parlanti nel freeware NoteTab e, dopo aver sostituto con degli underscore (trattini bassi) gli spazi nei nomi, ci siamo serviti del comando Text Statistics per avere alcune utili informazioni sui nostri dati, quali il numero di occorrenze, la frequenza e la percentuale di presenza dei vari nomi, dopodiché abbiamo utilizzato un foglio di calcolo[234] per ordinare i dati; di seguito riportiamo l'elenco delle prime venti posizioni disposte in ordine decrescente in base alla frequenza di apparizione:
| Parlante | Frequenza | % |
|---|---|---|
| personaggio_indefinito | 168 | 20.36 |
| personaggi_indefiniti | 45 | 5.45 |
| Bartolomeo_Ardito | 25 | 3.03 |
| Vittorio_Scuderi | 24 | 2.91 |
| popolo_indefinito | 20 | 2.42 |
| Giuseppe_Agozzino | 19 | 2.30 |
| Raimondo_Battaglia | 17 | 2.06 |
| Gerlando_Boccadoro | 15 | 1.82 |
| Speranza_Ardito | 14 | 1.70 |
| Filippo_Salvaggio | 14 | 1.70 |
| Raimondo_Dileo | 12 | 1.45 |
| uomo_dagli_occhialini_dorati | 11 | 1.33 |
| Serafino_Collica | 11 | 1.33 |
| Ignazio_Pirrera | 10 | 1.21 |
| capitano | 10 | 1.21 |
| Attilio_Barreca | 10 | 1.21 |
| Michelangelo_Teseo | 9 | 1.09 |
| Bartolomeo_Ardito_-_nipote | 9 | 1.09 |
Si noti la preponderanza dei personaggi indefiniti nei discorsi diretti, da soli i valori "personaggio indefinito" e "personaggi indefiniti" rappresentano ben il 25% circa dei parlanti nei discorsi diretti. Continuando ad esaminare questi dati è possibile effettuare altre considerazioni, l'elevato numero totale di personaggi parlanti, ben 174, offre un'ulteriore riprova del fatto che il romanzo sia costituito da "microstorie frantumate", si noti anche quanto numerosi siano quei personaggi che pronunciano solamente una o due battute, a dimostrazione della natura corale dei racconti. Altre considerazioni si potrebbero trarre continuando ad analizzare questi dati, d'altra parte anche altri dati avremmo probabilmente potuto ottenere dal nostro sorgente XML/TEI, ma un'analisi più ampia esula dagli obiettivi che ci siamo prefissati, rimandiamo questo lavoro ad altre circostanze, in questa occasione abbiamo soltanto voluto offrire un superficiale esempio delle possibilità che le codifiche dichiarative e gli strumenti informatici offrono agli studiosi come ausilio nell'analisi testuale.
Col primo esempio abbiamo visto un foglio che forniva delle statistiche sul testo, col secondo vediamo come sia possibile creare degli output di navigazione del testo specificamente concepiti per esigenze di analisi. In particolare con questo secondo progetto abbiamo voluto dimostrare come sia possibile creare un file ipertestuale che punti a tutte le occorrenze di un determinato elemento, e quindi utile per lo studio e l'interpretazione di determinati fenomeni. Nello specifico, a titolo esemplificativo, abbiamo realizzato un piccolo lavoro che crea un output HTML del testo di Baltico in cui tutti questi nomi sono evidenziati dal colore rosso nella riproduzione video, ed identificati mediante un ancora nel codice, in modo tale che fossimo in grado di realizzare una sorta di indice ipertestuale che consenta di puntare a tutte le occorrenze di un certo nome. In primo luogo abbiamo scritto un foglio di stile che ricreasse il codice XML di Baltico aggiungendo un attributo id con valore univoco a tutti gli elementi <name> del sorgente, in modo tale da poi poter generare a partire da questi id il nome (ossia la destinazione) delle varie ancore HTML cui gli indici dovranno puntare; si occupa di ciò il foglio dal nome copia e aggiungi attributi.xsl, il quale non fa altro che copiare l'intero sorgente XML e, mediante il template per l'elemento <name>, aggiungere un attributo id il cui valore è costituito dal valore dell'attributo id dell'elemento <div1> in cui <name> è contenuto e da un codice univoco generato dalla funzione generate-id().
Il secondo foglio di stile, da noi chiamato HTML con ancore.xsl[235], non fa altro che creare un output HTML di Baltico a partire dal nuovo sorgente XML arricchito con gli attributi id per gli elementi <name> prodotto col precedente foglio XSLT. In sostanza non si tratta altro che del medesimo foglio di stile per l'output HTML del romanzo che già abbiamo visto in precedenza, con l'unica differenza che è stato aggiunto un template per gli elementi <name> che si occupa di creare nell'output HTML un ancora in corrispondenza di ogni nome, di seguito ne riportiamo il codice[236]:
<xsl:template match="name">
<a name="{@id}" class="nome">
<xsl:apply-templates/></a>
</xsl:template>
Il terzo foglio di stile viene utilizzato per la creazione degli indici di navigazione; di seguito ne riportiamo il codice[237]:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output encoding="ISO-8859-1"/>
<xsl:param name="pp">Gerlando Boccadoro</xsl:param>
<xsl:template match="/">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="text">
NOME: <b><xsl:value-of select="$pp"/></b><br/>
<xsl:for-each select="//name[@key=$pp]">
<xsl:sort select="@key"/>
<a href="baltico.htm#{@id}">capitolo <xsl:value-of select="./ancestor::div1/@id"/></a><br/>
</xsl:for-each>
occorrenze: <xsl:value-of select="count(//name[@key=$pp])"/>
</xsl:template>
</xsl:stylesheet>
Questo codice XSLT opera sul sorgente XML modificato dal primo foglio di stile (quello con gli attributi id per gli elementi <name>) e crea una piccola interfaccia di navigazione che consente di puntare nel nuovo file HTML creato dal secondo foglio XSLT, alle occorrenze di un determinato nome. Di seguito riportiamo una schermata di questo output HTML visualizzata dentro il browser Internet Explorer 6.0:
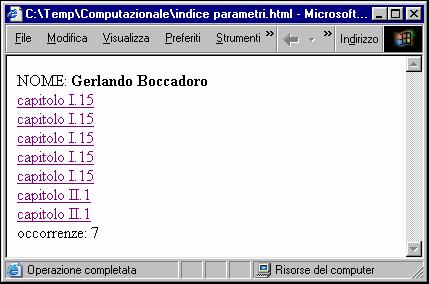
Come vediamo troviamo il nome analizzato[238], un link per ogni occorrenza in cui è specificato il capitolo dove questa compare ed infine il computo totale delle occorrenze; cliccando su uno dei link si viene portati nel punto preciso dell'output HTML dove compare il nome in questione[239]. Quello che abbiamo qui mostrato è soltanto un esempio senza una grande utilità effettiva nel caso concreto per lo studio del testo, quello che abbiamo voluto qui mostrare è l'opportunità, in accordo con l'attività di codifica, di costruire degli strumenti di navigazione ed interrogazione del testo che possano agevolare lo studioso durante la lettura e l'interrogazione delle opere letterarie per le necessità dell'analisi. Ad esempio usando le medesime metodiche qui illustrate si possono costruire degli indici di navigazione per ritrovare velocemente tutti i discorsi diretti di un certo personaggio ovvero con certe caratteristiche, o ancora indici di navigazione per qualsivoglia elemento, e quindi fenomeno testuale (fonetico, narrativo, linguistico, etc.) opportunamente codificato, tutto sta all'acume ed all'estro dello studioso.
.nome {font-family: Verdana, Geneva, Arial, Helvetica, sans-serif;
font-size: 12pt;
color:red;}