III.16. PDF E PRINT ON DEMAND
vedi: appendice 14, appendice 15, appendice 17.
Nel capitolo dedicato al Print-on-Demand nella seconda parte di questa relazione, abbiamo affermato che probabilmente, almeno per il prossimo futuro, sarà ancora la carta il supporto di lettura principale per i libri, elettronici e non; a riprova di ciò vi è il dato che vede crescere in tutti i paesi industrializzati il consumo totale di carta, crescita dei consumi che ovunque sembra riferirsi soprattutto alla carta formato A4, quella usata da stampanti e da fotocopiatrici. Il boom degli home computer e di internet, associato con lo sviluppo dei dispositivi di stampa personale, sembra proprio che, paradossalmente, abbia favorito la crescita del consumo mondiale di carta invece che rallentarlo: ciò dimostra come nel mondo digitale il testo digitale (fruizione ed archiviazione) sia ancora ben lungi dall'essere una realtà pienamente consolidata e diffusa.
Sulla base di queste considerazioni anche per il nostro lavoro sul romanzo di Collura abbiamo deciso di prevedere la possibilità di una "materializzazione cartacea" del testo elettronico di Baltico, abbozzando una sorta di applicazione per la stampa su richiesta (print on demand) basata sul formato Adobe PDF.
PDF è stato il pioniere dei formati per la distribuzione dei testi digitali e rappresenta oggi uno standard per i documenti elettronici ampiamente affermato; essendo figlio di Postscript, il linguaggio di descrizione della pagina sviluppato dalla Adobe, PDF esprime il meglio delle proprie potenzialità proprio con quelle applicazioni finalizzate alla stampa, pur mantenendo una buona resa a video. Nel corso della sua evoluzione il PDF ha visto una sua incarnazione come formato e-book, si ricordi l'esperienza Glassbook, che si è conteso a lungo la palma di miglior tecnologia per i libri elettronici con il rivale Microsoft LIT. Nel nostro lavoro, tuttavia, abbiamo deciso di non considerare primariamente la tecnologia Adobe da questo punto di vista, ma piuttosto come formato finale destinato alla stampa, questo per due ordini di motivi, il primo di natura economica, il secondo di natura pratica. Gli e-book PDF dispongono, o almeno dovrebbero, di particolari caratteristiche quali la presenza di tag[214] oppure di funzioni avanzate di navigazione del documento, che è possibile, al momento, aggiungere ai file soltanto grazie a costosi software commerciali. D'altra parte, la creazione di un e-book PDF curato nei particolari richiede in genere una buona dose di lavoro "manuale" da parte dell'assemblatore del libro digitale (definizione tag, copertina, salti pagina, ridefinizione layout e formattazione etc.) allorché ci si trovi a lavorare, come nel nostro caso, partendo da un testo codificato in XML.
Pertanto, avendo nel nostro progetto optato per l'adozione di tecnologie di elaborazione (il più possibile) automatica dei documenti per la produzione dei vari output di lettura del testo codificato e soprattutto a basso costo, abbiamo deciso di porre in secondo piano la realizzazione di una versione PDF di Baltico indirizzata principalmente alla fruizione su schermo.
Lo strumento, di cui ci siamo avvalsi per la definizione di un output stampabile dai dati XML del romanzo di Collura, è stato la tecnologia XSL-FO. L'Extensibile Stylesheet Language Formatting Objects (XSL-FO) è un vocabolario per specificare la semantica di formattazione, sviluppato congiuntamente ad XSLT, costituisce insieme ad XPath uno dei tre componenti di cui è composta la tecnologia XSL. Se si ricorda quanto detto nella prima parte della nostra relazione, XSL-FO nasce per essere utilizzato in accoppiata con XSLT, mentre il compito di XSLT è quello di trasferire, trasformare, i dati XML originari in una nuova struttura adatta alla riproduzione degli stessi, la funzione di XSL-FO è quella di definire le regole di formattazione di questa nuova struttura e sostanzialmente di fornire la struttura in cui trasferire i dati per mezzo di XSLT. I documenti XSL-FO vengono utilizzati in accoppiata con il Formatting Object Processor (FOP), una applicazione software la quale si occupa di effettuare il rendering (la formattazione grafica) del documento e produrre un nuovo documento di output adatto alla stampa oppure alla visualizzazione. L'attività di XSL per la produzione di output usando oggetti di formattazione (Formatting Object) consta di una serie di passaggi: dapprima il processore XSLT applica all'istanza XML sorgente le regole per la trasformazione del sorgente in una nuova struttura XSL-FO, la quale successivamente viene elaborata dal Formatting Object Processor che legge l'istanza FO risultante dall'elaborazione XSLT e produce documenti di output in formati come PDF, PCL (Printer control Language), testo o altro in base alle esigenze di agenti utente esterni. Lo schema seguente potrà aiutare a comprendere meglio i vari passaggi del processo appena illustrato:
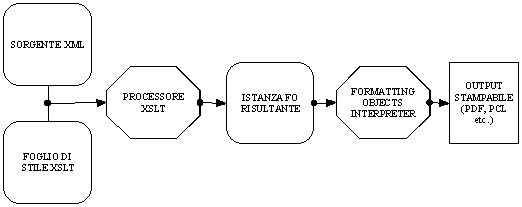
Dopo questa breve introduzione generale all'argomento passiamo ad illustrare come si è operato nello specifico per il nostro progetto; prima di procedere è, tuttavia, opportuna una precisazione. Il TEI Consortium ha messo a disposizione sul proprio sito una serie di fogli XSLT elaborati da Sebastian Rahtz per la trasformazione di istanze XML/TEI in documenti PDF; la soluzione realizzata dallo studioso inglese è basata sull'utilizzo di Passivetex, un sistema che adopera XSL-FO per produrre a partire da dati XML documenti PDF attraverso il software di compilazione per il linguaggio TeX, LaTeX. È necessario a questo punto fornire alcune informazioni al lettore; TeX è un linguaggio di programmazione per la composizione tipografica, ideato nel 1977 da Donald Knuth, un professore della Stanford University. La "compilazione" di un sorgente TeX produce un file in formato finale per la stampa. TeX viene soprattutto utilizzato per la pubblicazione di testi di carattere matematico-scientifico per le sue doti di riproduzione di formule e grafici anche molto complessi. Da principio il linguaggio non ebbe una grande diffusione a causa della sua complessità, in un primo momento, il suo utilizzo rimase limitato principalmente a tipografi e programmatori esperti. Tuttavia, nel 1985 Leslie Lamport sviluppò LaTeX, una raccolta di macro scritte in TeX che consentendo un approccio semplificato al linguaggio TeX ne favorirono la diffusione e lo sviluppo.
XMLTeX è un sistema per comporre file XML attraverso TeX, normalmente viene affiancato a LaTeX per trasformare i file XML in un documenti pronti per la stampa, attraverso un metodo di trasformazione degli elementi e degli attributi del file di origine in comandi di LaTeX. Realizzato da Sebastian Rahtz, PassiveTeX è un insieme di fogli di stile aggiuntivi, che in particolare consentono a XMLTeX (o altri compositori TeX) di elaborare file XSL-FO. Nel nostro progetto abbiamo deciso di non adottare la soluzione proposta nel sito del TEI Consortium, in primo luogo a causa della nostra scarsa conoscenza di TeX e dei programmi ad esso collegati, in secondo luogo poiché si è stimato che potesse esser utile proporre alla comunità degli studiosi una soluzione alternativa a quella offerta dal Tei Consortium e Sebastian Rahtz basata su di un software anch'esso gratuito e dalla minore difficoltà di installazione ed implementazione rispetto a PassiveTeX.
Il Formatting Object Processor adottato per il nostro progetto è stato Apache FOP 0.20.5, un'applicazione Java open source distribuita gratuitamente via Internet dalla Apache Software Foundation[215].
Le specifiche XSL-FO definiscono una collezione di oggetti, i formatting objects appunto, mediante i quali controllare l'impaginazione ed il layout generale dei documenti, questi costrutti sono dotati di una cospicua serie di proprietà, sotto forma di coppie "attributo=valore", con cui descrivere nel dettaglio tutte le caratteristiche di rappresentazione dell'oggetto (posizionamento, dimensioni, font, colore, etc.), una buona parte delle proprietà di formattazione usate in XSL-FO sono state riprese direttamente dalla specifica dei CSS (Cascading Style Sheet), tuttavia i FO hanno capacità di rappresentazione nettamente superiori agli stili CSS.
La struttura base di un file XSL-FO è la seguente:
<?xml version="1.0" encoding="UTF-8"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<fo:layout-master-set>
<fo:simple-page-master master-name="pagina_mastro">
<fo:region-body />
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="pagina_mastro">
<fo:flow flow-name="xsl-region-body">
<fo:block>testo</fo:block>
<fo:block>testo</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
Essendo un file XML, ogni documento XSL-FO si apre con la consueta dichiarazione XML.
<fo:root> è l'elemento radice dell'albero del documento e costituisce il contenitore per tutti gli altri oggetti; dentro l'elemento <fo:layout-master-set> vengono definiti mediante elementi <fo:simple-page-master> i modelli di impaginazione, le "pagine mastro"[216], del documento. Gli elementi <fo:simple-page-master> devono essere associati ad un attributo master-name che si può codificare con un valore a scelta e serve a fornire un nome univoco all'elemento; il nome è necessario per poter distinguere più master uno dall'altro, è inoltre indispensabile per permettere ai singoli gruppi di pagine (<fo:page-sequence>) di far riferimento al modello di impaginazione definito nel <fo:simple-page-master> mediante l'attributo master-reference.
All'interno dei margini fissati con gli attributi appropriati nell'elemento <fo:simple-page-master> si collocano delle regioni dichiarate attraverso gli elementi <fo:region-before>, <fo:region-after>, <fo:region-start>, <fo:region-end> e <fo:region-body>[217],questo ultimo elemento è l'unico obbligatorio, l'area definita dall'elemento <fo:region-body> contiene, sovrapposte, le altre quattro regioni corrispondenti alla testata, al piè di pagina ed ai margini destro e sinistro del corpo del documento. La seguente immagine mostra graficamente quanto appena detto:
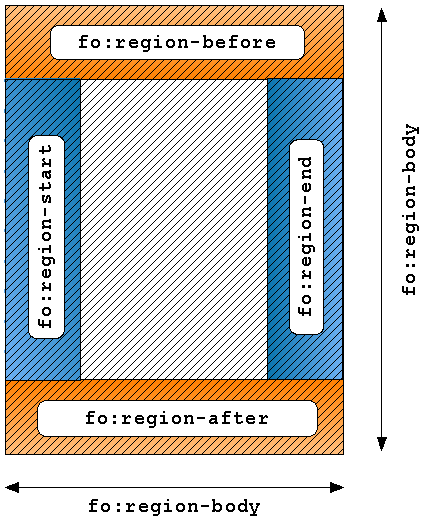
L'elemento <fo:page-sequence> contiene la definizione delle informazioni contenute nelle pagine che costituiranno il documento finale. Questo elemento rappresenta, come si evince dal nome, una sequenza di pagine, quali ad esempio un capitolo o una parte di un libro. Pertanto, un documento può avere più elementi <fo:page-sequence> distinti. L'attributo obbligatorio master-reference serve a specificare il riferimento al tipo di impaginazione, ossia alla "pagina mastro", alle regole di layout definite nell'elemento <fo:simple-page-master> collegato. L'elemento <fo:page-sequence> deve contenere necessariamente un unico elemento <fo:flow>, un oggetto contenitore che racchiude tutto ciò, testo ed altro, che viene distribuito nelle pagine. L'elemento <fo:flow> deve dichiarare, attraverso l'attributo flow-name, in quale regione della pagina si inserisce il flusso di contenuti in questione. Dentro <fo:flow> i contenuti sono ripartiti e strutturati mediante elementi "blocco", il principale di questi è l'elemento <fo:block> la cui funzione è quella di contenere sia testo lineare, sia altri blocchi (compresi altri elementi <fo:block>). Viene in genere adoperato per racchiudere i singoli paragrafi, può essere considerato come un equivalente dell'elemento <p> o dell'elemento <div> di HTML.
Passando ad esaminare il foglio di stile[218] per la trasformazione in XSL-FO del testo codificato in XML di Baltico, si nota che nei vari modelli viene riprodotta la struttura dei documenti XSL-FO appena illustrata[219]. Nel template del nodo radice, da cui come di consueto prende l'avvio l'elaborazione, troviamo oltre all'elemento radice delle istanze XSL-FO (<fo:root>) anche la definizione delle "pagine mastro" del documento (<fo:layout-master-set>); come si può osservare abbiamo definito un solo modello di impaginazione (<fo:simple-page-master>) per il nostro file, le regole di layout definite nell'elemento stabiliscono che le pagine del nostro documento dovranno avere un'altezza di 29.7cm ed una larghezza di 21cm, ossia le dimensioni di un foglio A4. Si è optato per dimensioni corrispondenti al formato A4, in quanto questo è il formato di pagina comunemente adoperato da stampanti e fotocopiatrici. Come detto, uno dei nostri obiettivi è stato quello di realizzare un rudimentale sistema di "print on demand", in cui i dati elettronici dell'archivio digitale potessero essere all'occorrenza "materializzati", stampati, anche con risorse esigue (un computer ed una stampante). Potrà sembrare pretenziosa la definizione di applicazione per il print-on-demand per questo lavoro che sostanzialmente non fa altro che realizzare dei file per la stampa da dei dati XML. Si tenga però presente che adottando le medesime tecnologie che in queste pagine stiamo via via illustrando è ipotizzabile, la creazione di un elementare box per la stampa dei testi digitali di un potenziale archivio elettronico; si ricordi che Apache FOP, il processore che abbiamo utilizzato, è in grado di inviare l'output elaborato direttamente alla stampante. Inoltre Apache FOP è un software, seppure "ancora giovane", che nasce non per essere utilizzato principalmente da linea di comando, ma per essere integrato in altre applicazioni (java, applicazioni lato server). Riesce quindi facile immaginare che volendo non sarebbe eccessivamente difficoltoso ed oneroso approntare un sistema di "stampa su richiesta" per i testi TEI/XML di un ipotetico archivio digitale. Vorremmo aggiungere che altrettanto semplice sarebbe, sulla base di quanto già visto nel capitolo sull'accessibilità, consentire agli utenti una personalizzazione, sulla base di proprie specifiche esigenze, delle caratteristiche tipografiche degli output di stampa (dimensioni e tipo di carattere, interlinea etc.); infatti, analogamente a quanto si è visto per il rendering a video anche gli output a stampa vengono generati dinamicamente a partire dai dati XML sulla base delle indicazioni fornite dall'utente ai software di elaborazione.
Tornando al nostro foglio di stile vediamo che l'elemento <fo:simple-page-master>, cui abbiamo dato nome di "principale" (master-name="principale"), definisce le dimensioni dei margini della pagina; all'interno dell'area delimitata da questi margini si trova la <fo:region-body>; anche per questa regione abbiamo definito dei margini, un margine superiore ed uno inferiore entrambi di 1.8cm. Si noti che la pagina mastro in questione definisce anche altre due regioni <fo:region-before> <fo:region-after>, praticamente intestazione e piè di pagina, si noti che l'estensione di queste due regioni è inferiore a quella dei margini di <fo:region-body>; infatti come sappiamo tutte le regioni diverse dal corpo del documento (<fo:region-body>) si sovrappongono a questo, se avessimo impostato una dimensione per queste aree superiore a quella dei margini di <fo:region-body>, avremmo rischiato che i contenuti di queste si potessero venire a sovrapporre con i contenuti del corpo del documento, ossia della <fo:region-body>.
Proseguendo nell'analisi del foglio di stile incontriamo il template del <teiHeader>; come vediamo non ha alcun contenuto, la sua funzione infatti è quella di escludere dall'elaborazione questo nodo con tutti i suoi figli. Di seguito il modello dell'elemento <front> dapprima, mediante il comando <xsl:apply-templates/>, invoca i modelli per gli elementi figli, che in questa circostanza si occupano della creazione della copertina/frontespizio del documento, e successivamente inserisce nell'output una serie di pagine contenenti le dediche e le epigrafi; coerentemente con quanto fatto per le altre elaborazioni anche in questa occasione questi elementi sono stati inseriti manualmente, probabilmente nel caso ci fossimo trovati a lavorare non su di un solo testo bensì su di un corpus di testi, avremmo cercato o di definire una pratica univoca per la codifica ed il trattamento di dediche ed epigrafi ovvero, sulla scorta peraltro di quanto fatto in progetti analoghi, avremmo optato per l'esclusione pressoché generalizzata dalla codifica di queste componenti del testo.
Uno dei modelli principali del nostro codice è, come è ovvio, quello dei nodi <div1>, elemento con cui nel sorgente XML, come il lettore dovrebbe ricordare, abbiamo marcato i singoli capitoli. Questo template crea una sequenza di pagine <fo:page-sequence> in cui racchiude il contenuto del capitolo. Nell'elemento <fo:page-sequence> mediante due elementi <fo:static-content>[220] vengono definiti una intestazione ed un piè di pagina fissi per tutte le pagine della sequenza. Come intestazione (xsl-region-before) di tutte le pagine del testo abbiamo scelto: "MATTEO COLLURA - BALTICO: edizione elettronica"[221]. Nel piè di pagina (xsl-region-after) abbiamo usato il comando <fo:page-number/> per produrre il numero di pagina corrente[222]. I contenuti testuali del capitolo vengono inseriti, come detto, all'interno del marcatore <fo:flow>, dove per mezzo del tag XSLT <xsl:apply-templates/> vengono invocati i template per gli elementi figli di <div1>, ossia i singoli paragrafi, i titoli di capitolo etc..
Tutti i contenuti dei capitoli, paragrafi, titoli e così via, sono stati racchiusi dentro elementi <fo:block> per mezzo dei rispettivi template. Si noti che nei modelli dei titoli di capitolo (<head>) di tipo ordinale e convenzionale si è fatto in modo che nell'elemento <fo:block>, che li deve marcare nell'output FO, fosse inserito un attributo id il cui valore è generato sulla base dell'attributo id dell'elemento <div1> genitore dell'<head> nodo contesto, sulla scorta di quanto già fatto nelle elaborazioni precedentemente analizzate; ciò anche in questo caso è servito per la creazione di un indice del documento. Se il lettore vorrà tornare per un momento ad esaminare il template del nodo radice noterà la presenza di due comandi <xsl:apply-templates/>, il secondo dei quali caratterizzato dall'attributo mode con valore index[223]. I modelli della modalità "index", i quali vengono attivati subito dopo la prima elaborazione dell'istanza XML sorgente, provvedono a creare un indice generale del documento. Anche in questa circostanza, come già visto nell'occasione della produzione dell'output HTML, tutto si basa su un sistema di ancore e riferimenti incrociati, in particolare il comando <fo:page-number-citation ref-id="{../@id}"/> restituisce il numero della pagina in cui occorre il Formatting Object il cui valore dell'attributo id corrisponde al valore del proprio attributo ref-id, e quindi nello specifico dà il valore della pagina in cui occorre il corrispettivo titolo di capitolo e perciò dell'inizio capitolo stesso. Mentre l'indice della versione HTML era basato su di un insieme di collegamenti ipertestuali, questo che stiamo illustrando è un indice "tradizionale" caratterizzato da riferimenti a numeri di pagina, ossia a pagine effettivamente esistenti. In appendice riportiamo alcune pagine stampate a partire dall'output PDF prodotto grazie all'elaborazione XSLT/XSL-FO del codice XML di Baltico, che mostrano il risultato finale di tutto questo processo appena illustrato.
Come detto all'inizio del capitolo non si è considerata prioritaria la creazione di una versione e-book PDF di Baltico; ciò nonostante non abbiamo totalmente escluso questa ipotesi, abbiamo pertanto cercato di ottenere questo risultato con gli strumenti a nostra disposizione. Abbiamo in più circostanze detto che il PDF è un formato orientato alla descrizione di pagina ed alla stampa, avendo quindi limitate caratteristiche di adattamento dinamico al device di visualizzazione come accade per il formato LIT o lo stesso HTML, occorre nella produzione di un e-book in questo formato adottare delle dimensioni della pagina che si adattino al meglio allo schermo del dispositivo su cui il file verrà aperto; l'optimum è quindi la realizzazione di output di lettura appositamente confezionati per specifiche categorie reader (Tablet PC, palmari, computer etc.), ove non si voglia o non si possa far ciò è prassi comune adottare per gli e-book PDF una dimensione di pagina di circa nove pollici di altezza per sei pollici di larghezza, misure che costituiscono un buon compromesso al fine di garantire una visualizzazione confortevole su di una vasta gamma di dispositivi ed allo stesso tempo consentirne la stampa senza difficoltà[224]. Tra le altre caratteristiche che contraddistinguono un file PDF destinato ad una fruizione a video vi sono la presenza dei segnalibri (bookmark), una caratteristica di navigazione dei file PDF, ed i cosiddetti tag PDF che dovrebbero garantire in una certa misura la possibilità di adattamento dinamico del documento PDF al device di lettura. Originariamente gli e-book PDF erano destinati ad essere fruiti grazie ad uno specifico lettore, l'Acrobat eBook Reader (ex Glassbook Reader); oggi questo programma è stato abbandonato dalla Adobe e le funzioni di e-book reader sono state integrate nel visualizzatore standard di file PDF , l'Acrobat reader che per l'occasione è stato ribattezzato Adobe Reader. A nostro modesto parere con questa nuova versione del prodotto della software house americana si è avuta se non proprio una perdita di funzionalità quanto meno una perdita di praticità del programma nell'utilizzo degli e-book; è oggi meno netta la distinzione fra un normale documento PDF e un e-book PDF. Dal punto di vista della protezione dei contenuti la Adobe offre una delle soluzioni più efficienti e versatili con il proprio Adobe Content Server, questa piattaforma per il DRM e la distribuzione di contenuti, come abbiamo già visto, ha una delle sue caratteristiche di spicco nel consentire il prestito dei libri elettronici, cosa impossibile al momento con altri sistemi di DRM, d'altra parte i suoi alti costi di licenza non la rendono appetibile per realtà accademiche o no profit. I file PDF prevedono dei meccanismi di protezione[225] standard contro la modifica non autorizzata dei documenti, tuttavia tale protezione può venire facilmente eliminata con alcuni software, tra i quali quello di una nota azienda russa che è possibile acquistare senza difficoltà dal sito internet della stessa.[226]
Nella realizzazione di una versione e-book PDF del testo di Baltico abbiamo cercato di tener conto di tutti questi elementi pur servendoci degli strumenti precedentemente descritti. La nostra attività ha preso l'avvio dal lavoro già svolto per il primo output PDF del romanzo di Collura, quello per la stampa, integrando e rielaborando i fogli di stile già creati in quel progetto per la produzione di un file che fosse dotato quanto più possibile di tutte quelle caratteristiche che contraddistinguono un e-book PDF secondo i canoni sopra descritti, pur usando le tecnologie XSLT/XSL-FO, Apache FOP e pochi altri strumenti gratuiti.
Per quanto riguarda le dimensioni pagina è bastato modificare le misure di altezza e larghezza in <fo:simple-page-master>, come si può notare dal codice del foglio di stile anch'esso riportato in allegato, si è definita un'altezza di 23cm ed un larghezza di 15cm, corrispondenti all'incirca alla dimensione di 9x6 pollici detta poco prima. Si sarà notato che in questo nuovo foglio XSLT nel <fo:layout-master-set> sono stati inseriti due <fo:simple-page-master>, la prima pagina mastro, identificata dal nome "cover" serve da modello di pagina per la copertina, la quale abbiamo riciclato dal progetto per la versione e-book LIT del romanzo, e che, seppure non indispensabile, costituisce un vezzo estetico che abbiamo voluto concedere al nostro lavoro. Più difficoltosa è stata l'inserzione nel nostro file dei segnalibro di navigazione (bookmark), allo stadio attuale dello sviluppo, XSL-FO non supporta i bookmark PDF[227], per fortuna Apache FOP, il processore FO da noi adottato, è dotato di un'estensione[228], che consente l'elaborazione dei segnalibri. Identificati dal namespace "fox" i comandi per la definizione dei bookmark, situati nel template della radice immediatamente dopo l'elemento <fo:layout-master-set>, sono <fox:outline> e <fox:label>, il primo si occupa di stabilire la destinazione del segnalibro, il secondo invece fornisce il nome del bookmark che apparirà nella barra dei segnalibri di Adobe Acrobat. Il sistema per la definizione dei segnalibri in XSLT, che ricalca da vicino quello già adoperato per la creazione della Table of Contents della versione OEBPS del romanzo, si basa su di una serie di elaborazioni <xsl:for-each> su tutti i nodi <div0>, <div> e su i nodi <head>, in cui l'attributo type abbia valore 'tem', la struttura di ancore e riferimenti incrociati si basa sul consueto meccanismo fondato sull'utilizzo degli attributi id e n degli elementi <div1> e <div0> già più volte visto in precedenti fogli di stile, si noti soltanto l'utilizzo della funzione translate() nella definizione dell'etichette dei titoli dei capitoli per rimuovere i ritorno a capo, che in fase di codifica nel sorgente abbiamo mantenuto così come occorrevano nella fonte cartacea. Per il resto il nostro foglio di stile si rifà in tutto e per tutto a quello approntato per la versione "stampabile", con l'unica differenza della minore dimensione delle pagine e dell'assenza dell'indice finale. Di seguito riportiamo alcune schermate che mostrano come l'output PDF ottenuto si presenti nell'Adobe Reader 6.0:
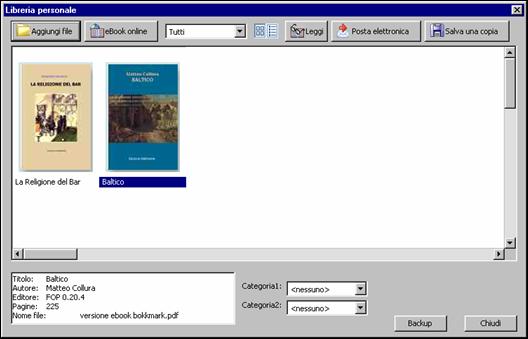
L'area di Adobe Reader Libreria personale con la miniatura della copertina
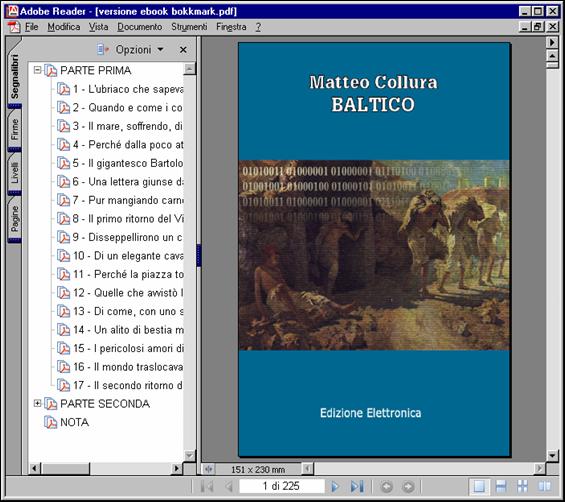
Segnalibri e copertina

La prima pagina del testo visualizzata in modalità schermo intero
Una volta conclusa l'elaborazione automatica e prodotto l'output PDF abbiamo voluto eseguire su questo alcuni piccoli lavori ulteriori, riguardanti la protezione del documento ed i metadati dello stesso, coerentemente con quanto gia fatto in precedenza, anche in questa occasione ci siamo serviti di programmi freeware.
Ogni documento PDF può essere associato a dei metadati contenenti il titolo, l'autore, il soggetto della pubblicazione etc. che ne agevolano l'archiviazione e l'indicizzazione. Il processore FO da noi utilizzato non permette di inserire automaticamente queste informazioni nel file finale; pertanto, abbiamo deciso di giovarci di un piccolo programma freeware dal nome PDF info, prodotto dalla Bureausoft[229], che permette di inserire e modificare manualmente queste informazioni. Un'altra funzione avanzata con cui abbiamo ritenuto opportuno accompagnare il nostro file, sebbene fossimo consci della possibilità di aggirare questa protezione, è stata l'impostazione di alcune limitazioni di sicurezza; abbiamo, infatti, disabilitato la possibilità di modificare il documento, stabilendo la necessità di inserire una password per l'esecuzione di operazioni di modifica e cambiamento delle impostazioni di sicurezza: per far ciò ci siamo serviti del software open source pdftk[230] e della relativa interfaccia grafica guipdftk[231] realizzata da un giovane programmatore di nome Dirk Paehl.
Ci preme far notare che quanto mostrato in queste pagine è stato realizzato con programmi a costo zero; d'altra parte, buona parte dei software e per certi versi delle stesse tecnologie utilizzate sono ancora molto giovani e, quindi, verosimilmente soggette a futuri miglioramenti.
<http://www.adobe.com/products/acrdis/createbooks.html>
07 Ottobre 2000, (19 Maggio 2004).