III.10. REVISIONE DELLA CODIFICA
Subito dopo la codifica si è proceduto alla revisione del lavoro svolto alla ricerca di errori sia nella trascrizione, sia nella marcatura del testo.
In primo luogo si è verificata la correttezza del contenuto testuale e la sua conformità con la fonte al fine di individuare eventuali errori (battiture accidentali, caratteri sbagliati o mancanti), introdotti nel testo dal programma di OCR e sfuggiti ad una prima analisi oppure frutto di digitazioni involontarie durante l'attività di codifica; si è, pertanto, avuto cura di rileggere tutto il testo "digitale", verificando la perfetta corrispondenza di questo con quello della fonte cartacea.
In secondo luogo si è provveduto alla ben più complicata revisione della marcatura TEI/XML. Della verifica del rispetto dei vincoli sintattici imposti nella DTD come sappiamo si occupa il parser XML; tuttavia, pur nella piena conformità con le regole della DTD può capitare di commettere degli errori nella codifica, si può sbagliare nell'aprire o chiudere un elemento non delimitando perfettamente il testo a cui dovrebbe far riferimento oppure si può semplicemente dimenticare di marcare un elemento o ancora più succedere che, per distrazione o stanchezza, si adoperino elementi o valori di attributo errati. Per cercare di ovviare a tutti gli sbagli, che può aver commesso nell'immissione del markup il novello amanuense elettronico, è opportuno dedicarsi subito dopo la codifica ad un attento e scrupoloso esame della stessa.
Per cercare di facilitarci almeno in parte il duro lavoro di correzione, abbiamo messo in atto alcuni, per così dire, trucchi. Un errore, in cui siamo incorsi più volte, è stato l'aver dimenticato di codificare con l'opportuno tag <q> il discorso diretto oppure di aver chiuso il marcatore prima della fine del discorso; per tal motivo, partendo dalla riflessione che ogni discorso diretto è nel nostro testo racchiuso sempre tra doppie virgolette ad angolo («. . .»), corrispondenti nella codifica alle entità numeriche "«" e "»" , servendoci della funzione "trova" dell'editor di testi[158] ci siamo accertati che prima di ogni "«" si trovasse un tag <q> e viceversa che dopo ogni "»" si incontrasse il rispettivo tag di chiusura </q>.
Un altro espediente si è adottato per il controllo dei page break: è naturale che questi elementi si devono susseguire nel file in ordine crescente, abbiamo perciò provveduto a creare un piccolo foglio di stile XSLT[159] che si occupasse di mandare in output in un file HTML il valore dell'attributo n di tutti i tag <pb> del documento. Riportiamo di seguito il codice del file XSLT in questione:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" version="4.0"/>
<xsl:template match="/">
<xsl:for-each select="//pb">
<xsl:choose>
<xsl:when test="position() mod 10 = 0">
 <xsl:value-of select="@n"/> <br/>
</xsl:when>
<xsl:otherwise>
 <xsl:value-of select="@n"/> 
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ecco, invece, l'output prodotto dal nostro foglio di stile dopo essere stato applicato ad una parte del <body> visualizzato nel browser Microsoft Internet Explorer 6.0:
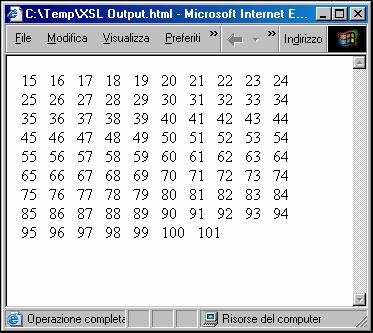
Come si può notare si è ottenuta una sequenza numerica corrispondente ai valori degli attributi n dei tag <pb>; è stato, quindi facile accorgersi di eventuali errori, numeri mancanti o ripetuti nella successione che avrebbero indicato inequivocabilmente un errore o il mancato inserimento di un marcatore di salto pagina. Tralasciamo di commentare il codice del foglio XSLT in quanto di questo linguaggio parleremo più ampiamente nel prosieguo della trattazione allorché affronteremo la parte relativa alla produzione dei diversi file di output proprio grazie a tale tecnologia; in questa sede diremo soltanto che il foglio effettua mediante l'espressione X-Path "//pb" una ricorsione su tutti gli elementi <pb> dell'istanza XML e si occupa di mandare in uscita il valore n degli elementi selezionati, per migliorare la leggibilità del file HTML risultante dalla trasformazione abbiamo inserito nella ricorsione una semplicissima elaborazione condizionale[160] che provvede a mandare a capo la sequenza numerica ogni dieci elementi.
A prescindere comunque, dai sistemi adottati per cercare di automatizzare ed agevolare il lavoro, il grosso dell'attività di revisione è stato effettuato rileggendo con cura tutto il codice del file, prestando la massima attenzione ad accidentali errori o sviste.