II.8. COME ABBIAMO LAVORATO
A titolo esemplificativo delle potenzialità del testo digitale desideriamo illustrare il procedimento da noi seguito per l'archiviazione ed il trattamento delle fonti, che abbiamo adoperato per l'elaborazione di questa relazione. Nella celeberrima dicotomia echiana fra "apocalittici" ed "integrati" riteniamo di poter ascrivere la nostra posizione (spero senza integralismi) a quella degli integrati. Possedendo una buona confidenza col computer abbiamo cercato di organizzare il lavoro in modo tale da essere in varie fasi agevolati dal "cervello elettronico"; tuttavia, lo sforzo della valutazione e dell'organizzazione dei materiali oltre che dell'elaborazione e stesura finale della relazione è stato inesorabilmente frutto della fatica del nostro "cervello umano". Ecco in dettaglio come si è proceduto[101].
La prima fase dell'elaborazione di ogni relazione è notoriamente la raccolta e la catalogazione dei materiali. Per la collezione delle fonti ci siamo giovati ampiamente di internet che abbiamo scandagliato in lungo ed in largo con l'ausilio del motore di ricerca Google[102], in assoluto il nostro preferito. Siamo, inoltre, riusciti grazie al prezioso aiuto della Professoressa Lucrezia Lorenzini a costituirci una buona bibliografia di testi "tradizionali".
Per quanto riguarda la catalogazione del materiale in nostro possesso, sebbene, visto l'argomento trattato, una parte delle nostre fonti fosse già in formato digitale (e-book, pagine web), abbiamo provveduto anche per le fonti su supporto cartaceo (libri, riviste, atti) a digitalizzare le parti per noi di interesse. Per far questo ci siamo servito di un vecchio scanner[103] piano formato A4 della Primax e di un ottimo software OCR[104] di produzione russa ABBYY FineReader 6. Abbiamo poi provveduto a trasformare i documenti elettronici acquisiti da internet oppure frutto della digitalizzazione dal cartaceo, in formato Microsoft Word 2002, ciò ci ha permesso di effettuare una schedatura di tutte le nostre fonti, infatti tale formato consente di applicare delle metainformazioni al file. La scheda delle proprietà del file accessibile dal menù file/proprietà del programma si presenta così:
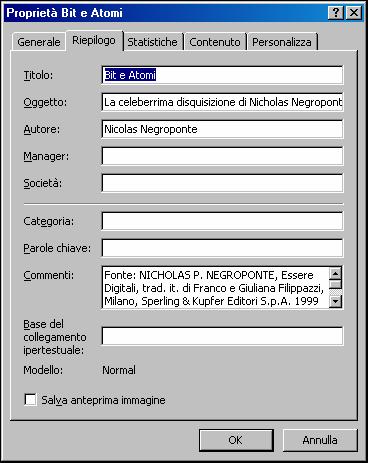
il vantaggio di usare tale funzione consiste soprattutto nel fatto che queste informazioni sono semplicemente accessibili da sistema operativo (nel nostro caso Windows 98 SE). La seguente immagine illustra come si presenta da Risorse del Computer la cartella contenete le nostre fonti:
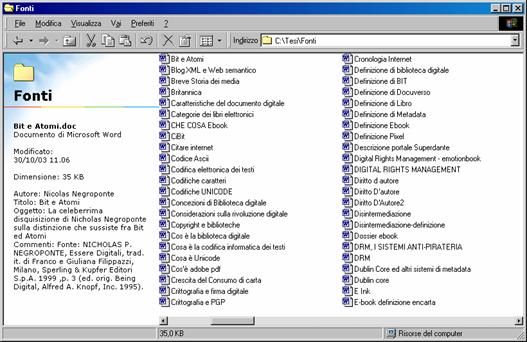
come si può vedere sulla sinistra appaiono le informazioni riguardanti la fonte, da noi inserite al momento della catalogazione.
Abbiamo optato per un formato di un software di videoscrittura anche perché così abbiamo potuto agevolmente aggiungere evidenziazioni alle parti più significative usufruendo delle funzioni del programma. Per quanto riguarda le fonti in formato e-book (pdf e lit) non abbiamo sentito la necessità di una conversione in formato Word in quanto abbiamo potuto utilizzare i funzionali strumenti messi a disposizione dai rispettivi programmi di lettura degli e-book.
Man mano che la consultazione delle fonti procedeva e cominciavamo ad intravedere connessioni tra le stesse, abbiamo realizzato una scaletta con collegamenti ipertestuali che puntavano ai vari testi o a determinate parti di questi. Sebbene per far ciò fossero numerose le possibilità a nostra disposizione, esistono software ad hoc e lo stesso Word consente di impostare iperlink, abbiamo preferito creare delle pagine Html vista la nostra buona conoscenza del linguaggio.
In ambito informatico circola uno scherzoso adagio che dice che esistono solo due tipi di dati: quelli di cui esiste il backup[105] e quelli che non sono stati ancora persi; rendendoci conto del rischio di poter perdere informazioni per noi molto importanti ci siamo da subito preoccupati di effettuare quotidiani salvataggi dei dati in nostro possesso, ci siamo serviti per questo di due cd riscrivibili, uno da usare i giorni pari uno quelli dispari, e di una porzione di spazio nel nostro secondo hard-disk. Inoltre non volendo rimanere vincolati da un formato proprietario accessibile esclusivamente con un unico programma, abbiamo salvato anche, come copia di backup, tutti i documenti da noi convertiti in formato Word in HTML oppure RTF, in modo da non rimaner preclusi dall'accesso ai nostri dati, magari in un momento importante in cui non avremmo potuto fermarci per cercare di risolvere il problema, da un eventuale danneggiamento di Microsoft Word.
Un importante aiuto ci è venuto dal computer nella fase cruciale della nostra relazione, quella della redazione, infatti per destreggiarci al meglio nel cospicuo numero di fonti a nostra disposizione ci siamo giovati di un software "The Sleuthhound!", un vero e proprio motore di ricerca per documenti digitali. Grazie a questo programma siamo riusciti ad interrogare a fondo ed in breve tempo tutti i materiali a nostra disposizione. Il software supporta gli operatori boleani per affinare la ricerca, ad esempio come abbiamo visto il termine e-book compare nei testi nella doppia dizione con trattino e senza, a noi è bastato indicare come parole chiave della nostra ricerca "ebook OR e-book" per ottenere tutte le pagine in cui questo termine era contenuto indipendentemente dalla grafia. Il programma inoltre già dall'interfaccia di ricerca permette di accedere al contenuto testuale del documento evidenziando le occorrenze trovate nel testo, cosicché si è subito in grado di avere un'idea generale del contenuto della fonte e eventualmente decidere di aprirla se necessario. Il programma supporta i principali formati dei documenti digitali doc, pdf, txt, html solo per citarne alcuni.
Nella stesura di questa relazione ci siamo giovati anche di alcuni strumenti di consultazione in formato elettronico, il Dizionario della lingua italiana De Mauro e l'Enciclopedia Microsoft Encarta, inoltre, dato che numerose nostre fonti erano in inglese, ci siamo avvalsi largamente del programma Babylon, un particolare software di traduzione grazie al quale basta clickare su di una parola per ottenerne immediatamente la traduzione. Da quanto detto, è possibile evincere chiaramente che già oggi, seppure con strumenti ancora troppo giovani, si possono ottenere, grazie alla tecnologia informatica, importanti vantaggi dall'utilizzo dei testi digitali.