III.5. CODIFICA
Dopo la digitalizzazione della fonte cartacea ha potuto prendere il via la codifica del testo.
III.5.1. I livelli di codifica
La prima decisione da prendere ha riguardato cosa codificare; sulla scia di quanto già fatto sia nel progetto TIL sia da GriseldaOnLine, il processo di trascrizione e codifica si è limitato esclusivamente al contenuto testuale della fonte, trascurandone l'aspetto materiale, inoltre tutti i materiali paratestuali non d'autore o non relativi al testo in sé (indice dei contenuti, note, etc.) sono stati tralasciati, gli unici fenomeni materiali della fonte mantenuto nella codifica sono stati i salti pagina occorrenti nell'edizione fonte.
A tal proposito nell'ambito del progetto TIL è stato elaborato un criterio di classificazione delle fonti e dei livelli di codifica, cui queste possono essere sottoposte, in seguito adottato anche dal progetto Biblioteca Italiana (BibIt).
Il comitato editoriale di TIL ha originariamente deciso di suddividere tutte le possibili fonti di un'opera in due classi:
-
fonti primarie:
- manoscritti
- incunaboli
- edizioni a stampa antiche
- edizioni a stampa notevoli (es. prime edizioni, etc.)
- edizioni diplomatiche a stampa
- edizioni a stampa anastatiche
-
fonti secondarie:
- edizioni a stampa moderne
- edizioni critiche moderne
Per le fonti primarie sono considerati rilevanti sia il contenuto testuale, sia i fenomeni materiali riscontrati sul documento originale, in tal caso inoltre si è deciso di affiancare alla trascrizione della fonte anche una digitalizzazione della stessa in formato grafico; la trascrizione e codifica di questo tipo di fonti deve pertanto approssimare quanto più possibile il livello di edizione diplomatico-interpretativa.
Per le fonti secondarie invece il processo di trascrizione e codifica si limita esclusivamente al contenuto testuale, trascurando l'aspetto materiale della fonte. Nella pratica questo comporta che tutti i materiali paratestuali non riconducibili direttamente all'autore o comunque estranei al testo in sé, per come questo è attestato nella tradizione (introduzione, prefazione, indice dei contenuti, note, etc.), presenti sull'edizione fonte sono tralasciati; inoltre ogni fenomeno materiale occorrente sulle pagine viene omesso, eventuali fenomeni di evidenziazione vengono codificati in modo funzionale; l'unico aspetto materiale della fonte che va mantenuto sono i salti pagina presenti nell'edizione fonte, in quanto possono essere utili ai fini di riferimento e citazione del testo.
In relazione alla natura incrementale del vasto markup TEI, che permette diversi tipi di codifica sulla base di esigenze interpretative e funzionali diverse, ed in riferimento alla segmentazione delle fonti gli studiosi di TIL hanno individuato cinque livelli di codifica, cui ciascun testo può esser sottoposto:
- livello 1: codifica della struttura editoriale del testo, di un limitato gruppo di fenomeni editoriali intralineari e linguistici;
- livello 2: codifica di un insieme di caratteristiche strutturali intralineari e linguistiche, codifica di semplici caratteristiche filologiche, eventuale introduzione di riferimenti incrociati e collegamenti ipertestuali; codifica avanzata dei metadati;
- livello 3: codifica di fenomeni testuali complessi in vista di applicazione di analisi avanzate (struttura semantica, narrativa, retorica, morfosintattica, etc.);
- livello 4: trascrizione diplomatica di una fonte primaria;
- livello 5: edizione critica di un opera.
I livelli 3, 4 e 5 non vanno necessariamente considerati come successivi su scala temporale o di complessità, ma piuttosto come livelli paralleli di articolazione del processo di codifica. È inoltre evidente che i livelli 4 e 5 sono applicabili esclusivamente a una o più fonti primarie.
Nella scala di classificazione elaborata dagli studiosi romani, il nostro lavoro può sostanzialmente essere ricondotto al primo livello di codifica con qualche "sconfinamento" nel secondo livello.
III.5.2. Il set di caratteri
Preliminare alla codifica del testo è stata la scelta del set di caratteri da utilizzare per la memorizzazione del contenuto; infatti, è bene ricordare che i file XML sono praticamente dei file di testo. Di default XML adotta il charset UTF-8 che, come sappiamo nelle prime 256 posizioni corrisponde perfettamente con il code set ISO 8859-1 o ISO Latin 1; il testo di Baltico generalmente non fa uso di caratteri particolari che avrebbero potuto creare problemi in fase di validazione[133] o trasferimento del documento; si sarebbe potuto quindi ignorare il problema dei caratteri, d'altra parte sappiamo che soltanto il set ISO 646 IRV (coincidente con il vecchio set ASCII a sette bit) è interpretato correttamente in qualsiasi piattaforma informatica e da qualunque applicazione; non a caso TEI prescrive l'adozione di questo charset[134] per i testi destinati all'interscambio, mentre per tutti i caratteri non inclusi in questo code set stabilisce l'uso delle entità carattere definite negli insiemi pubblici rilasciati dalla ISO, tali entità incluse nella DTD TEI sono, ad esempio, utilizzate anche nel linguaggio HTML.
Abbiamo ritenuto lungimirante, al fine di favorire la più ampia interoperabilità possibile del documento codificato, pur adottando UTF-8, adoperare delle entità per tutti quei caratteri non compresi nelle prime 128 posizioni di questo charset, ossia per i caratteri eccedenti l'ISO 646 IRV, ovvero tutte le lettere accentate ed alcuni simboli grafici quali le virgolette. Tuttavia a differenza di quanto prescritto nelle guidelines della Text Encoding Initiative invece di adoperare le entità di carattere definite da ISO, come ad esempio "è", abbiamo preferito adottare le rispettive entità numeriche, come ad esempio "è", le quali sono supportate nativamente da XML; ciò è stato fatto principalmente per due motivi: in primo luogo per svincolarsi dalla necessità di associare sempre il documento XML alla relativa DTD, infatti le entità di carattere per poter essere utilizzate devono essere specificate nella DTD, utilizzare entità numeriche invece non impone questo vincolo. Personalmente riteniamo che in numerose circostanze possa rivelarsi vantaggioso il distribuire una istanza XML soltanto come documento ben formato, una volta verificatane la validità sintattica, infatti soprattutto per documenti di grosse dimensioni, quale appunto un'opera letteraria, i tempi di validazione possono allungarsi andando ad aggiungersi ai tempi di elaborazione di altre attività sul documento XML. Si pensi ad esempio alla trasformazione dinamica in HTML di un file XML per mezzo di XSLT, al tempo di elaborazione del foglio di stile si aggiunge quello per la validazione sintattica del documento, attività questa, a nostro modesto parere, pleonastica se ci si è già accertati in partenza della validità del documento. Il secondo motivo che ci ha indotto a servirci di entità numeriche, è stato l'aver constatato che in numerose circostanze si rivelano maggiormente "gradite" nei processi di elaborazione, soprattutto con alcuni software per il trattamento dei materiali XML.
Per la sostituzione di tutte le lettere accentate ed altri caratteri non inclusi nella tavola ASCII a sette bit, ci siamo serviti del software Search and Replace prodotto dalla Funduc Software Inc., il quale, con un processo automatico, si è occupato di rimpiazzare tutti i caratteri in questione con le rispettive entità numeriche.
III.5.3. Gli strumenti per la codifica
Prima di partire con la codifica effettiva del testo è stato indispensabile selezionare ed approntare gli strumenti per codificare "materialmente" il testo, ossia per applicare i tag ai file provenienti dalla digitalizzazione della fonte cartacea.
Dopo un'accurata valutazione la nostra scelta è caduta su due programmi[135] Altova Xmlspy 5[136] e NoteTab 4.9[137].
Xmlspy 5 è uno dei più completi e versatili editor XML al momento in commercio; tale software è stato adoperato principalmente per la revisione del testo codificato, la validazione sintattica dei file XML e, nella fase più avanzata del lavoro, per la preparazione dei fogli di stile XSLT; a causa degli alti costi di licenza del programma in questione ci siamo serviti della versione "trial"[138] del software esclusivamente per il periodo di prova di trenta giorni.
NoteTab è invece un editor di testo avanzato, una sorta di evoluzione del blocco note di Windows, che fornisce numerosi strumenti per l'editing e la marcatura dei documenti "text based" come appunto i file XML. Una delle funzioni di spicco di questo software è la possibilità di creare delle proprie librerie di tag, denominate clipbook, e barre di pulsanti personalizzate con cui applicare la marcatura ai file di testo. Prima di procedere alla codifica di Baltico abbiamo pertanto provveduto a creare una nostra clipbook, e la relativa barra pulsanti, contenente i tag TEI che prevedevamo di adoperare.
NoteTab, in virtù di queste sue potenzialità, ha costituito lo strumento principale nella marcatura di base del testo; un altro grosso vantaggio di NoteTab è costituito dal fatto che nella sua versione "Light" questo software è completamente gratuito.
III.5.4. Struttura dei documenti TEI
Una volta definita tutta questa serie di particolari preliminari si è potuti partire con la codifica effettiva del testo.
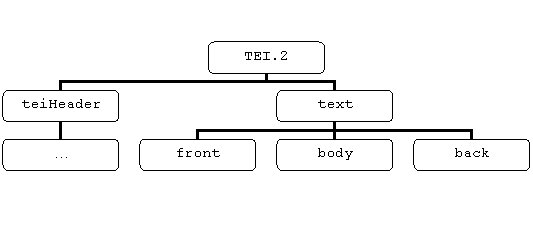
Ogni documento TEI, che ricordiamo è anche un documento XML valido, è caratterizzato dall'elemento radice <TEI.2> dal quale discendono due elementi figli <teiHeader> e <text>, i quali dividono praticamente in due parti il documento: il TEI header contenente i metadati ossia le informazioni bibliografiche ed editoriali relative al documento TEI ed alla sua fonte, ed il TEI text in cui trova posto il testo vero e proprio.
Il TEI header, il quale costituisce il frontespizio elettronico della pubblicazione digitale, consta di quattro parti: <fileDesc>, <encodingDesc>, <profileDesc>, <revisionDesc>, solo la prima è obbligatoria e deve quindi necessariamente essere presente, le altre tre sono opzionali.
L'elemento text si divide in tre[139] elementi:
- <front> (opzionale): contiene tutti i materiali di tipo avantestuale che tipicamente precedono il corpo del testo nelle edizioni a stampa, dalla pagina del titolo, al frontespizio, ad eventuali introduzioni o prefazioni.
- <body> (obbligatorio): comprende il contenuto testuale vero e proprio, al suo interno si susseguono, continuando a scendere nella struttura gerarchica dell'albero del documento, ulteriori divisioni: capitoli, paragrafi etc..
- <back> (opzionale): racchiude tutti gli annessi ed appendici che possono seguire la parte principale del testo, quali ad esempio: postfazioni, indici, glossari e materiali peritestuali in genere.
Schematicamente un testo unitario conforme alla DTD TEI presenterà una struttura di questo tipo:
<TEI.2>
<teiHeader>
[Frontespizio elettronico (Metadati)]
</teiHeader>
<text>
<front>
[Materiali dell'avantesto]
</front>
<body>
[Testo]
</body>
<back>
[Materiali che seguono il testo]
</back>
</text>
</TEI.2>
Ecco invece come può essere rappresentato graficamente l'albero del documento TEI: