III.14. XML DATA ISLAND
vedi: appendice 6 e appendice 7
Oltre che mediante trasformazione XSLT è possibile accedere a dati XML anche per mezzo di tecniche di collegamento dati (data binding). Ad esempio, nelle pagine HTML questo risultato può essere ottenuto attraverso la creazione di "isole di dati XML" (XML data island) con elementi HTML standard collegati ad elementi XML[198]. Mentre con la trasformazione XSLT, come si evince appunto dal termine, i dati vengono inseriti, "trasformati", in una nuova struttura, per lo più di rappresentazione, con le tecniche di XML data island si fornisce una maschera, un'interfaccia per l'accesso ai dati sulla scorta, un po', di quanto avviene in ambito database.
Al fine di investigare ed illustrare il più ampio ventaglio di possibilità di rappresentazione dei testi letterari sottoposti a codifica elettronica XML, abbiamo realizzato una piccola interfaccia HTML per la riproduzione su schermo di Baltico sfruttando tecniche di data binding, anche in questo caso in appendice viene riportato integralmente il codice sia della pagina HTML di collegamento ai dati, sia del foglio XSLT che, come vedremo fra poco, si è reso necessario per la modellazione dei dati originari in una nuova struttura idonea all'utilizzo come data island.
La tecnologia XML data island viene adoperata al meglio con dati rigidamente strutturati e schematizzati, sul modello dei database, e proprio precipuamente per l'utilizzo con i database XML è stata concepita, di per sé, quindi, non si presta bene all'adozione con dati non ordinati rigidamente[199], quali quelli di un testo letterario sottoposto a markup dichiarativo, come appunto la versione XML/TEI del romanzo di Collura da noi realizzata. Si è reso, dunque, necessario rimodellare i dati XML/TEI originari in nuova struttura adeguata ad essere usata come data island da incorporare nella nostra pagina HTML di interfaccia; per far ciò, anche in questa occasione, non siamo potuti naturalmente prescindere dall'uso di XSLT, che però, come vedremo, in questo caso è stato utilizzato in modo, vorremmo dire, "creativo". Ci teniamo a precisare che quanto da noi realizzato, almeno sulla base delle nostre conoscenze, è il primo esempio, perlomeno per quanto riguarda l'ambito nazionale, di utilizzo di tecniche di XML data island per la presentazione di testi letterari XML/TEI.
L'uso di questa tecnologia è stato dettato anche dal proposito di produrre una interfaccia di visualizzazione del testo nel browser web che, a differenza dell'output HTML di Baltico già descritto, non presentasse un'unica lunga pagina da leggere scorrendo progressivamente il testo, alla stessa stregua di un moderno "volumen" elettronico, bensì una serie di "pagine" da sfogliare come nei "codex".
In effetti, in occasione della prima trasformazione XSLT avremmo potuto fare in modo di realizzare un output costituito da più pagine HTML; tuttavia, al momento attuale dello sviluppo della tecnologia XSLT, che ricordiamo essere ancora alquanto giovane, la produzione di output su più file non si presenta abbastanza agevole adoperando gli strumenti standard: abbiamo, pertanto, deciso di abbandonare questa strada.
Come detto l'obiettivo che ci siamo prefissi usando XML data island è stato quello di ottenere dei ben precisi risultati nella visualizzazione del testo con un'interfaccia, che fosse caratterizzata da una serie di schermate di lunghezza non eccessiva, in modo tale da eliminare o ridurre al minimo la necessità dello scrolling[200], così da emulare, in certo qual modo, su schermo la consueta pratica dello sfogliare le pagine. In realtà, nel concepire il tutto avevamo a mente come modello principale l'interfaccia del Microsoft E-book Reader. Uno dei primi problemi che ci siamo trovati ad affrontare è stato, dunque, rimodellare i dati originari TEI in una struttura dall'organizzazione più idonea all'utilizzo con XML data island[201] e stabilire quale dovesse essere la lunghezza dei blocchi di testo adatta alle nostre esigenze; non volevamo, infatti, che ogni pagina eccedesse di troppo l'aria di visualizzazione di una schermata video alla risoluzione di 1024x768[202]. Infine, dopo numerosi tentativi abbiamo deciso di riproporre su schermo la medesima disposizione delle pagine (intesa come blocchi di testo) della nostra fonte cartacea, per far ciò ci siamo giovati dei tag <pb> della sintassi TEI che nella codifica sono serviti appunto per registrare i salti pagina nell'edizione fonte.
Questa scelta non si è rivelata di semplice attuazione ed ha richiesto una certa "fantasia", rimodellando i dati per le esigenze di XML data island, nell'uso degli strumenti offerti da XSLT. Come sappiamo <pb> è un tag milestone, un tag vuoto usato per indicare dove occorrono nel flusso del testo i salti pagina, è sostanzialmente un segnaposto che non racchiude al proprio interno testo o altri elementi come fanno gli altri marcatori, sorgeva dunque il problema di come delimitare a partire dai tag di page break le singole pagine in opportuni blocchi di testo; la soluzione è venuta da un uso per così dire "eterodosso" di XSLT.
Passando ad esaminare il foglio di stile XSLT riportato in allegato possiamo notare che sostanzialmente questi non fa altro che trasferire i dati del nostro file XML/TEI in un nuovo file XML dalla struttura assai semplice, composto da un elemento radice di nome <liber> il quale possiede un solo elemento figlio <pag>, che è il contenitore per i due elementi <pagina>, in cui è contenuto il testo della pagina, e <numero> dove abbiamo voluto registrare il numero della pagina corrispondente nella fonte cartacea.
Il file si apre con il template dell'elemento radice il quale scrive oltre al tag radice del nuovo XML <liber> i marcatori <pag> e <pagina>, di seguito crea una sorta di piccolo frontespizio elettronico di questo nuovo file prelevando dal TEI Header alcune informazioni: autore, titolo dell'opera, edizione elettronica, responsabili della codifica e della pubblicazione.
Subito dopo <xsl:apply-templates/> invoca gli altri template ed infine il modello chiude il file scrivendo </pagina>,</pag> e </liber>, ciò produce una sorta di sistema ad incastro che combinandosi con il modello successivo per i tag <pb> consente il raggiungimento del nostro scopo.
Infatti il template per il tag <pb>, che costituisce un po' il fulcro di questa elaborazione, grazie a comandi <xsl:text> (necessari per mantenere la buona formazione del file XSLT) ogni qual volta incontra nel sorgente un tag <pb> provvede prima a chiudere i tag <pagina> e <pag> e successivamente dentro un tag <numero> manda in output il numero della pagina elaborata (prelevandolo dall'attributo n di <pb>) dopodiché apre il tag <pagina>. Sia il marcatore <pag> sia quello <pagina> vengono chiusi dall'elaborazione del successivo <pb> nel sorgente TEI, infatti ogni <pb> nell'elaborazione rappresenta la fine del precedente blocco e contestualmente l'inizio di quello nuovo[203], così facendo, come forse si sarà compreso, siamo riusciti a realizzare un file ben formato in cui le singole pagine dell'edizione fonte (ovvero i corrispondenti blocchi di testo) sono racchiuse dentro coppie di marcatori <pagina>...</pagina>.
L'interfaccia HTML della sorgente di dati XML da noi creata è concepita in modo tale da visualizzare sequenzialmente le pagine, le quali possono essere sfogliate mediante una serie di pulsanti posti alla base del documento. Sotto il testo viene riportato il numero della pagina, abbiamo optato per indicare il numero della corrispondente pagina dell'edizione fonte piuttosto che ricreare una nuova numerazione per questa versione digitale, ritenendola più utile per effettuare eventuali raffronti e per avere una idea delle caratteristiche di disposizione ed impaginazione dell'edizione originale.
Di seguito riportiamo una schermata dell'interfaccia HTML:
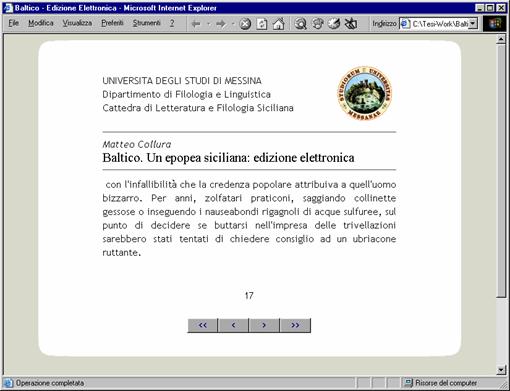
Esaminando invece il codice di questa pagina, riportato in appendice, possiamo vedere che si tratta di un semplicissimo file HTML il cui layout principale è definito da una tabella, l'isola di dati XML è richiamata mediante il tag <XML id="baltico" src="island.xml"/>, mentre le informazione contenute nel sorgente XML (inserite dentro la tabella) vengono prelevate grazie ai marcatori <SPAN datasrc="#baltico" datafld="pagina"></SPAN> e <SPAN datasrc="#baltico" datafld="numero"></SPAN>, che come si sarà compreso, fanno riferimento al contenuto dei tag <pagina> e <numero> della sorgente dati XML da noi precedentemente creata e a cui abbiamo dato il nome di island.xml.